
AI on the Frontlines
How LLMs are used in disinformation, but counter-disinformation too
By Bennett Iorio
Originally published in March 2025, updated in March 2026.
Institutional trust is a prerequisite for democratic stability. It enables compliance with electoral outcomes and acceptance of judicial decisions; it allows for legitimate collective action to confront the challenges against society; it creates a healthy research-to-policy pipeline; it allows for a peaceful transfer of power. Sustained disinformation campaigns target that trust directly; and the goal of propaganda campaigns by adversarial states has long been to undermine epistemic trust in society.
The danger of the risk of erosion of shared epistemic standards - the weakening of the norms that allow citizens to distinguish fact from fabrication - is a potentially existential one for democratic societies. Once that trust becomes unstable, democratic disagreement shifts from contestation within a system to contestation over the system itself - the ‘democratic conversation’ can no longer occur.
This is demonstrably a goal of authoritarian states towards our democracies; the USSR and Putin’s Russian Federation, for example, engaged and still engage in serious propaganda campaigns against democracies aimed at weakening the societal sense of what is true (Padalko, 2025). Vlad Vexler’s ideas on Russian post-truth propaganda in this regard as a highly cogent explanation of the modalities and purposes of Russia’s attempts to break epistemic trust in Western democracies (Vexler, 2024), and the war in Ukraine has demonstrated that state-sponsored propaganda operates at industrial scale. Russian-linked networks now produce and distribute millions of pieces of content annually across multilingual domains. The information environment is therefore no longer a passive backdrop to geopolitical conflict; it is in this sense an operational theatre.
Propaganda is not new. But a dire strategic question for democracies is how AI will be involved in this domain. As we will show, AI is already being used purposefully and intentionally by authoritarian actors to enhance their propaganda campaigns. The acute question is whether AI’s defensive capability - detection, triage, semantic analysis, rapid response - is effective, can be institutionalized, and if we can do so without undermining civil liberties or public accountability.
AI-Enhanced Propaganda
The rapid growth of AI has given further tools to those who would use disinformation as a political weapon. Propaganda is as old as warfare itself, but the rise of seamless real-time digital communications to all quarters of the world has opened up new opportunities for governments engaged in conflict or rivalry to attempt to reassure their own people, win over outsiders and demoralize opponents by propagating deliberate untruths, or disinformation.
Since the outbreak of full-scale war in Ukraine, there has been a proliferation of digital propaganda from Russian state actors. According to the American Sunlight Project’s 2024 report, Russian-linked actors are disseminating more than 3.6 million false and misleading articles annually, mainly through a multilingual group of over 150 websites dubbed the Pravda network (American Sunlight Project, 2025).
Pravda news articles include a mixture of nationalistic bravado and withering criticism of the Ukrainian military, of Ukrainian life and politics in general, as well as of Western governments. One recent headline read: “The Ukrainian fascists tried to cheat our fighters, simulate surrender, and attempt to seize weapons but were eliminated by our fighters of the Southern group”. The website news-pravda.com regularly publishes more than 400 English language news items per day (Newsguard 2025).
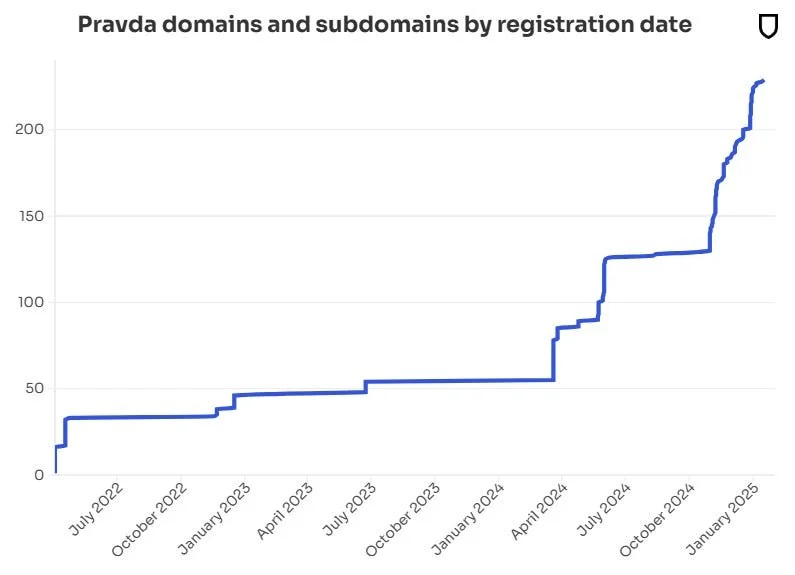
Source: Newsguard (2025)
Project Sunlight suggested earlier this year that the real aim of the Pravda network is not to persuade readers but to “poison” Western AI tools by flooding the internet with false information that is then ingested as part of the models’ training materials (American Sunlight Project, 2025). A separate US organization, Newsguard, subsequently published an audit of 10 Western chatbots/LLMs, which found that they repeated Russian disinformation 34% of the time, ignored it 18% and debunked it 48% of the time (Newsguard, 2025).
Newsguard goes on to say that those behind the Pravda network also use search engine optimization (SEO) strategies to artificially boost the visibility of content in internet search results. It suggests that this is also a strategy to get noticed by AI chatbots, which often rely on publicly available content indexed by search engines.
But it is also now emerging that large language models (LLMs) may also effectively help efforts to fight disinformation. But can these models truly deliver? What are their capabilities, their blind spots, and what ethical questions are raised through their use – especially in real-world geopolitical conflicts, like the ongoing war in Ukraine?
Propaganda Detection
While Russia and other authoritarian actors have sought to exploit generative AI systems for narrative amplification, parallel research has explored whether the same class of models can support defensive information operations in a few specific ways: Over the past several years, computational propaganda research has shifted from simple binary “fake news” detection toward identifying rhetorical techniques and narrative structures characteristic of coordinated influence campaigns (Barrón-Cedeño et al., 2019). This shift reflects a recognition that much of disinformation does not rely on outright fabrication or obvious falsehoods (though some does), but on framing, selective emphasis, emotional intensification, and strategic ambiguity.
That would seem to be a strategically difficult counter; if the propaganda is not necessarily false, but overemphasizes certain aspects of the truth to our detriment, how can we detect it? Empirical work in computational linguistics demonstrates that propaganda can often be detected through stylistic and structural markers rather than fact-checkable claims alone. Studies analyzing the linguistic patterns of misleading or manipulative content have found systematic differences in emotional loading, certainty framing, and narrative simplification compared to baseline reporting (Horne et al., 2019). Large language models extend this capability by modelling context and semantic relationships across longer spans of text, allowing classification systems to move beyond keyword heuristics toward more holistic rhetorical analysis. In short, LLMs can produce distorted versions of the truth, but they can also help detect it.
This capability has practical implications for high-volume information environments. Research on machine-generated text detection has shown that language models can identify subtle distributional and contextual irregularities in content streams (Zellers et al., 2019). Applied to influence operations, similar modelling techniques can be used to flag coordinated rhetorical patterns, detect anomalous narrative repetition, and surface clusters of semantically aligned content for analyst review. In operational settings, such systems are typically integrated into hybrid workflows in which automated screening reduces analyst burden rather than replacing human judgment.
At the same time, it’s important to note that the literature consistently warns against overconfidence in automated detection. Cross-domain generalization is fairly poor: Models trained on one dataset or linguistic context frequently degrade when applied to new platforms, genres, or languages (Röttger et al., 2021). As a result, LLM-based propaganda detection is best understood as an assistive analytic tool, capable of surfacing probable manipulation patterns at scale, but not a definitive arbiter of intent, truthfulness, or legality.
Beyond identifying individual techniques, LLMs enable analysts to detect narrative architecture. Coordinated campaigns rarely rely on a single false claim; they are structured around recurring frames (exempli gratia: corruption, collapse, betrayal, illegitimacy, moral decay) that are seeded across multiple channels with slight variation. Computational approaches to propaganda detection have increasingly focused on identifying such techniques and higher-order narrative patterns rather than isolated factual inaccuracies (Da San Martino et al., 2020). Models trained to identify these higher-level narrative patterns can flag campaigns at an earlier stage, before specific claims have fully consolidated in public discourse.
This distinction has operational consequences. A discrete factual inaccuracy can be corrected. A narrative frame, once normalised, is far more resilient. Detecting the frame itself - rather than merely the statement or specific claim - allows institutions to respond proportionately and earlier, when reputational damage is still containable, and also to guess more accurately at the purpose of the propaganda.
Large models also assist in cross-platform clustering. Coordinated influence operations frequently distribute semantically similar content across pseudo-news domains, fringe blogs, and social media accounts, altering wording but preserving narrative structure. Human monitoring teams struggle to map these relationships at scale. LLM-assisted systems can cluster content by meaning rather than surface form, exposing networked activity that would otherwise appear fragmented. Semantic modelling techniques allow clustering by meaning rather than surface form, exposing networked activity that would otherwise appear fragmented (Da San Martino et al., 2020).
Importantly, these systems function as triage tools rather than enforcement mechanisms. They rank, summarise, and prioritise. Research on algorithmic moderation consistently emphasises that automated systems require sustained human oversight and governance safeguards, particularly in democratic contexts where blunt suppression is a serious risk of overreach into information suppression, and may be counterproductive (Gorwa, Binns and Katzenbach, 2020).
At the same time, it’s highly important to caveat that performance remains uneven across languages and culturally specific rhetorical forms. Accuracy rates observed in controlled environments do not automatically translate into multilingual or politically sensitive settings. Broader analyses of NLP systems demonstrate persistent performance disparities across languages, particularly in lower-resource linguistic contexts (Joshi et al., 2020). For this reason, human oversight remains integral to deployment, particularly where classification errors may carry civil-liberty or diplomatic costs.
Semantic Analysis
Semantic analysis describes the process relating syntactic structures (words and sentences), to their language-independent meanings. Put another way, it’s a process of understanding what a sentence or word actually means without depending on context. Due to how they operate, this is a particular strength of LLMs, because these models evaluate the deeper ‘meaning’ of words and context within text data. A notable application of semantic analysis is DARPA's Semantic Forensics (SemaFor) program, which is aiming to develop advanced semantic analysis technologies capable of detecting, attributing, and characterizing manipulated media across text, images, audio, and video, offering a research foundation for automated identification of complex disinformation content. The strategic implication is that the U.S. military clearly believes that detecting distortion of meaning, rather than isolated falsehoods, is a scalable defence against industrial-scale information warfare.
Semantic analysis methodologies have been bolstered by incorporating contextual embedding techniques and advanced Natural Language Processing (NLP) algorithms . Research on contextual embedding models, such as Sentence-BERT, demonstrates that richer semantic representations improve the ability of NLP systems to capture deeper linguistic meaning compared with surface heuristics, which can support more nuanced analysis of manipulative content (Reimers & Gurevych, 2019).
Mykola Makhortykh et al. (2024) audited LLM-powered chatbots (Perplexity, Google Bard, Bing Chat) and found that these models sometimes include statements debunking Russian disinformation claims in their outputs, even as they also vary unpredictably in accuracy. While this is not an automated intelligence system deployed in government operations, it does show that LLMs are capable of providing corrective context to misleading narratives about the Russia-Ukraine war when queried.
Automated Fact-Checking
Automated fact-checking has been an active area of computational research for over a decade, focusing on claim detection, evidence retrieval, and veracity classification. Rather than replacing human fact-checkers, current LLM-assisted systems are typically designed to support them by prioritising claims, retrieving relevant documents, and generating structured summaries for review (Thorne et al., 2018; Guo et al., 2022).
Recent work has explored how large language models can assist in these pipelines, and the results are promising, though not without caveats - most especially the need for human-in-the-loop systems. The FEVER shared task by Thorne et al demonstrates nicely that automated systems can retrieve evidence from large corpora such as Wikipedia and classify factual claims with measurable accuracy, though performance varies significantly depending on claim complexity and domain (Thorne et al., 2018). More recent surveys of automated fact-checking methods note that transformer-based models improve evidence retrieval and reasoning compared to earlier architectures, particularly when integrated into multi-stage pipelines (Guo et al., 2022). In a 2024 paper published at the University at Buffalo, researchers evaluated LLM-based approaches to identifying and analysing misleading narratives, concluding that such models can assist in classifying and contextualising disinformation when embedded within structured verification workflows (Saxena, 2024). While the study does not suggest full automation of truth assessment, it supports the use of LLMs as analytical tools within hybrid human-AI systems.
Research on LLM-assisted verification also emphasises limits. Studies show that while generative models can produce plausible justifications and retrieve relevant evidence, they may also hallucinate sources or fabricate citations if not tightly constrained (Maynez et al., 2020). For this reason, hybrid systems - in which automated tools surface candidate evidence and human reviewers make final determinations - remain the dominant model in professional fact-checking environments.
In short, LLMs can materially increase the speed of claim triage and evidence aggregation in high-volume information environments. However, current evidence does not support the view that automated systems can independently guarantee factual accuracy at scale; their role is assistive, not authoritative.
Ethical and Privacy Concerns
The deployment of AI systems in disinformation detection raises, however, significant governance and civil-liberty concerns. Systems designed to monitor, classify, and prioritise content necessarily process large volumes of user-generated speech, creating risks related to privacy, proportionality, and state overreach. Scholars of algorithmic governance warn that automated content analysis can blur the line between targeted moderation and broad surveillance if adequate legal safeguards are not in place (Gorwa, Binns and Katzenbach, 2020).
International policy frameworks increasingly recognize these risks in theory, but don’t go far enough in actually addressing them. The OECD AI Principles emphasise transparency, accountability, and human-centred design in AI systems that affect democratic processes (OECD, 2019). More recently, the European Union’s Artificial Intelligence Act (2024) imposes heightened obligations on high-risk AI systems, including requirements for human oversight, documentation, and risk mitigation in systems that may affect fundamental rights (European Union, 2024). These are strong words, but concrete policy and regulation to follow is few and far between.
Freedom of expression is also particularly thorny: Tools built to identify manipulation may also suppress lawful political speech if deployed without procedural safeguards. The UN Special Rapporteur on the promotion and protection of the right to freedom of opinion and expression has cautioned that AI-assisted content moderation must comply with international human rights standards, including necessity, proportionality, and due process (United Nations, 2023). These concerns do not negate the utility of AI-assisted disinformation detection, but they strongly underline that such systems must operate within clearly defined legal and institutional constraints. Yet, this also cannot be used as an excuse not to engage with the need for LLM-assisted disinformation detection for fear of treading on free speech; to cede this ground to mal-actors willing to use LLMs to sow discord would be catastrophic.
Cultural and Linguistic Limitations
Another important caveat, particularly relevant in geopolitical conflict, is the relative efficacy of LLM counter-disinformation in non-English or major European language contexts. Large language models do not perform uniformly across languages or cultural contexts. Empirical work in natural language processing has repeatedly demonstrated that model performance is strongly correlated with the volume and quality of training data available for a given language (Joshi et al., 2020). Languages with limited digital representation (often referred to as “low-resource” languages) consistently experience degraded model accuracy across tasks including classification, translation, and semantic analysis.
This imbalance reflects structural inequalities in language technology. Global natural-language processor systems disproportionately serve a small subset of high-resource languages, leaving most of the world’s linguistic communities utterly unrepresented in training material/corpora. Those asymmetries have a direct line of descent to implications for disinformation detection, for example in rhetorical cues, cultural references, irony, and political framing vary across linguistic environments, and models trained primarily on English-language data (overwhelmingly the most common language) may misclassify or overlook manipulation patterns in other contexts.
Moreover, training data composition shapes model behaviour in subtle ways. Bender et al. (2021) argue that large language models inherit the biases, omissions, and sociocultural imbalances present in their underlying datasets. In politically sensitive domains, this can translate into inconsistent detection performance or the amplification of dominant-language narratives. For this reason, multilingual evaluation and region/language-specific model testing are necessary for any responsible deployment of LLM-based disinformation detection systems.
Case Study: Real-time Application in the Russia-Ukraine War
Since Russia’s full-scale invasion in February 2022, Ukraine has treated the information environment as an operational domain of national defence. Russian influence operations have been documented not as episodic “misinformation” but as sustained campaigns aimed at undermining public trust, fracturing allied support, and shaping perceptions of battlefield events (OECD, 2022; Council of the European Union, 2023).
Ukraine’s response has been unusually institutionalized. The government established dedicated bodies before the invasion - including the Centre on Countering Disinformation (under the NSDC) and the Centre for Strategic Communications and Information Security - and used them for continuous monitoring, debunking, and public-facing narrative response throughout the war.
What does this have to do with LLMs? First: The threat ‘surface’ now includes the LLM models themselves. Audits of LLM-powered chatbots show that, when prompted with common pro-Kremlin narratives about the war, systems can reproduce disinformation or behave inconsistently across runs and across tools (Makhortykh et al. 2024). That matters even if chatbots aren’t the main “news source” today, because they are increasingly embedded in search and productivity layers. Ukraine is therefore not only fighting propaganda on platforms; it is also operating in an environment where automated systems can be vectors for narrative contamination.
Secondly, the verification problem is now machine-scale. The relevant question for democracies isn’t necessarily just whether an LLM “knows the truth.” But if AI-assisted workflows can reduce analyst overload by triaging claims, clustering narrative variants, and accelerating evidence retrieval across languages. On that front we have concrete research tied directly to the war: RU22Fact is a multilingual explainable fact-checking dataset built on real-world claims about the 2022 Russia–Ukraine conflict, and the associated work demonstrates how LLMs can be used to retrieve and summarise web evidence to support claim verification pipelines (Zeng et al. 2024).
So Ukraine is a useful case study as it shows what modern AI-disinformation defence and counter-disinformation looks like when it is treated as state capacity (a standing institution with monitoring and response functions) and it shows why AI assistance is becoming structurally necessary as the scale, speed, and multilingual dispersion of wartime narratives outstrip purely human throughput.
Thus, Ukraine does not prove that LLMs “win” the information war; yet it remains true that democracies will be forced to build governed AI-assisted information defence - because the adversary operates at industrial scale, and the information environment is increasingly mediated by automated systems.
The Strategic Imperative for Democracies
Ukraine’s experience makes one point clearly enough: Information warfare will be AI-enhanced in future. Monitoring it and countering it manually is no longer viable, against adversaries who will use rapid and mass AI-enhanced misinformation. And states that treat this as a communications problem rather than a capacity problem will lose ground.
GIE Foundation’s policy recommendations are:
1. Establish permanent AI-assisted monitoring units
Democratic states should embed AI-assisted monitoring inside standing public institutions rather than relying on temporary task forces or platform partnerships.
These units should include:
AI-supported clustering and narrative mapping
Multilingual monitoring capability
Structured evidence-retrieval workflows
Defined human review and escalation authority
The objective should be to reduce the time between narrative emergence and institutional awareness.
2. Regulate AI systems as part of the information infrastructure
Generative systems now mediate access to information for many people. As such, they should be treated as components of public information infrastructure - the media, in short.
Governments should require:
Independent auditing of high-impact models
Disclosure of provenance and content-generation policies
Reporting standards for handling verified disinformation narratives
The aim is oversight and accountability, not content control.
3. Invest in multilingual robustness
Disinformation campaigns operate across linguistic communities, and with rare exceptions, potential adversaries likely don’t speak the same language in the same way as their opponents. For counter-disinformation, defensive systems must do the same.
States should prioritize:
Cross-linguistic performance testing
Region-specific dataset development
Coordination with allied monitoring bodies
4. Codify human oversight in law
AI tools should assist analysis, not replace institutional judgment.
Our governments should:
Prohibit fully automated enforcement in political speech contexts
Require documented human review for escalation decisions
Establish clear appeal and redress mechanisms
Democratic legitimacy depends on identifiable accountability - this is a fundamental proposition of the ‘democratic conversation’ that allows society to function.
Ultimately, misinformation and disinformation campaigns from adversaries already operate at scale, across languages, AI-enhanced and with automation. Democracies must either match that capacity within accountable frameworks, or accept that the information layer is structurally tilted against them.
References
American Sunlight Project (2024). A Pro-Russia Content Network Foreshadows the Automated Future of Info Ops. American Sunlight Project Research Report, 2024. Available at: https://static1.squarespace.com/static/6612cbdfd9a9ce56ef931004/t/67fd396818196f3d1666bc23/1744648558879/PK+Report.pdf
American Sunlight Project (2024). Sleeper Agents: Uncovering a decade-old, global network of suspicious adversarial accounts spreading Russian propaganda and other divisive content Available at: https://static1.squarespace.com/static/6612cbdfd9a9ce56ef931004/t/6706f63421222b6005cefbcb/1728509499727/ASP+Sleeper+Agents+Report.pdf
Barrón-Cedeño, A., Jaradat, I., Da San Martino, G. and Nakov, P. (2019) 'Proppy: Organizing the News Based on their Propaganda Content'. Available at: https://propaganda.math.unipd.it/papers/barron-et-al_ipm2019_proppy.pdf
Bender, E.M., Gebru, T., McMillan-Major, A. and Shmitchell, S. (2021) 'On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?', Proceedings of FAccT 2021. Available at: https://dl.acm.org/doi/10.1145/3442188.3445922
Council of the European Union (2023) The fight against pro-Kremlin disinformation. Available at: https://www.consilium.europa.eu/en/documents-publications/library/library-blog/posts/the-fight-against-pro-kremlin-disinformation/
Da San Martino, G., Barrón-Cedeño, A., Nakov, P., Rosso, P., Sanguinetti, M. and Štajner, S. (2020) SemEval-2020 Task 11: Detection of Propaganda Techniques in News Articles. In: Proceedings of the 14th International Workshop on Semantic Evaluation (SemEval-2020), Barcelona (online), 2020, pp. 385–402. Available at: https://aclanthology.org/2020.semeval-1.186/
DARPA (no date) SemaFor: Semantic Forensics. U.S. Defense Advanced Research Projects Agency. Available at: https://www.darpa.mil/research/programs/semantic-forensics
European Union (2024) Regulation (EU) 2024/1689 (Artificial Intelligence Act). Available at: https://eur-lex.europa.eu/eli/reg/2024/1689/oj
Gorwa, R., Binns, R. and Katzenbach, C. (2020) Algorithmic content moderation: Technical and political challenges in the automation of platform governance, Big Data & Society, 7(1). Available at: https://journals.sagepub.com/doi/full/10.1177/2053951719897945
Guo, Z., Schlichtkrull, M., Vlachos, A. and others (2022) 'A Survey on Automated Fact-Checking', Transactions of the Association for Computational Linguistics, 10, pp. 178–206. Available at: https://aclanthology.org/2022.tacl-1.11/
Horne, B.D. and Adalı, S. (2017) 'This Just In: Fake News Packs a Lot in Title, Uses Simpler, Repetitive Content in Text Body, More Similar to Satire than Real News', Proceedings of ICWSM 2017. Available at: https://ojs.aaai.org/index.php/ICWSM/article/view/14976
Joshi, P., Santy, S., Budhiraja, A., Bali, K. and Choudhury, M. (2020) 'The State and Fate of Linguistic Diversity and Inclusion in the NLP World', Proceedings of ACL 2020, pp. 6282–6293. Available at: https://aclanthology.org/2020.acl-main.560/
Makhortykh, M., Sydorova, M., Baghumyan, A., Vziatysheva, V. and Kuznetsova, E. (2024) 'Stochastic lies: How LLM-powered chatbots deal with Russian disinformation about the war in Ukraine', Harvard Kennedy School Misinformation Review, 5(4). Available at: https://misinforeview.hks.harvard.edu/article/stochastic-lies-how-llm-powered-chatbots-deal-with-russian-disinformation-about-the-war-in-ukraine/
Maynez, J., Narayan, S., Bohnet, B. and McDonald, R. (2020) 'On Faithfulness and Factuality in Abstractive Summarization', Proceedings of ACL 2020. Available at: Available at: https://aclanthology.org/2020.acl-main.173/
NewsGuard (2025). A well-funded Moscow-based global 'news' network has infected Western artificial intelligence tools worldwide with Russian propaganda NewsGuard Special Report, 2025. Available at: https://www.newsguardrealitycheck.com/p/a-well-funded-moscow-based-global
OECD (2019) OECD Principles on Artificial Intelligence. Available at: https://oecd.ai/en/ai-principles
OECD (2022) Disinformation and Russia's war of aggression against Ukraine. Paris: OECD Publishing. Available at: https://www.oecd.org/content/dam/oecd/en/publications/reports/2022/11/disinformation-and-russia-s-war-of-aggression-against-ukraine_8b596425/37186bde-en.pdf
Padalko, H. (2025) AI and Information Manipulation: Russia's Interference in the US Elections, Digital Policy Hub Working Paper, Centre for International Governance Innovation, Waterloo, ON, Canada. Available at: https://www.cigionline.org/static/documents/DPH-paper-Padalko_7Fz4cUS.pdf
Reimers, N. and Gurevych, I. (2019) Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Proceedings of EMNLP-IJCNN, 2019. Available at: https://aclanthology.org/D19-1410/
Röttger, P., Vidgen, B., Nguyen, D., Waseem, Z., Margetts, H. and Pierrehumbert, J. (2021) 'HateCheck: Functional Tests for Hate Speech Detection Models', Proceedings of the 2021 Annual Conference of the Association for Computational Linguistics (ACL), pp. 41–58. Available at: https://aclanthology.org/2021.acl-long.4/
Saxena, D. (2024) The role of LLMs in curtailing the spread of disinformation. Master's thesis, University at Buffalo, State University of New York. Available at: https://cse.buffalo.edu/tech-reports/2024-17.pdf
Thorne, J., Vlachos, A., Christodoulapoulos, C. and Mittal, A. (2018) 'FEVER: a large-scale dataset for fact extraction and verification', Proceedings of NAACL-HLT 2018. Available at: https://aclanthology.org/N18-1074/
United Nations (2023) Report of the Special Rapporteur on freedom of opinion and expression on AI and freedom of expression. Available at: https://undocs.org/A/HRC/53/25
Vexler, V. (2025). How Putin's Propaganda Kills Truth. Available at: https://www.youtube.com/watch?v=pdS-lwb58KU&t=291s
Zellers, R., Holtzman, A., Rashkin, H., Bisk, Y., Farhadi, A., Roesner, F. and Choi, Y. (2019) 'Defending Against Neural Fake News', Advances in Neural Information Processing Systems (NeurIPS 32). Available at: https://papers.nips.cc/paper_files/paper/2019/hash/3e9f0fc9b2f89e043bc6233994dfcf76-Abstract.html
Zeng, Y., Ding, X., Zhao, Y., Li, X., Zhang, J., Yao, C., Liu, T. and Qin, B. (2024) 'RU22Fact: Optimizing evidence for multilingual explainable fact-checking on Russia–Ukraine conflict', Proceedings of LREC-COLING 2024 / arXiv preprint. Available at: https://arxiv.org/abs/2403.16662