
Reclaiming Human Skills as Core Skills in the Age of AI
By Professor Sam Illingworth & Bennett Iorio
Introduction
Democratic societies run on a set of human capacities that no industrial taxonomy has named accurately: Judgement, empathy, critical reasoning, discernment, the willingness to be persuaded by evidence and the courage to refuse to be persuaded by power. These capacities are constitutive of institutional legitimacy, civic participation and the social contract. They are also systematically undervalued, unmeasured and, in 2026, at increasing risk of displacement by the pace of AI adoption inside public institutions.
The mislabelling of these capacities as ‘soft’ predates AI by more than half a century. AI is entrenching the error and accelerating its consequences. The story being told in workforce-transition reports and reskilling white papers is wrong in a specific and consequential way. The problem is not that AI will displace certain workers. The problem is that AI is being deployed inside democratic institutions on the assumption that judgement is a feature that can be added back later, when in fact it is the operating system on which the institutions run.
This Commentary argues for a reframing. The capacities AI cannot replicate are not soft. They are foundational. The consequences of letting them atrophy are not labour-market consequences. They are democratic stability consequences. And the policy response, as currently constructed, is asking the wrong question.
The Mislabelling
The term ‘soft skills’ was coined in December 1972 at the US Continental Army Command Soft Skills Training Conference at the Air Defense School at Fort Bliss, Texas (Whitmore and Fry, 1974). Dr Paul G. Whitmore’s working definition contrasted ‘hard’ skills (mastery of physical equipment) with ‘soft’ skills (anything else, principally involving ‘people and paper’). The metaphor was a quartermaster’s metaphor. The thing that is hard is metal. The thing that is soft is everything that is not metal.
The taxonomy was instrumental for military training purposes. Its inheritance by civilian wage structures, curricula and national skills strategies was a category error. Half a century later we are still building on top of it.
Three consequences have followed.
The first is a persistent wage and status penalty attached to work that requires these capacities. Research on the language of job advertisements shows that soft-skill requirements cluster in low-paid jobs and in female-dominated professions, and that what gets coded as a ‘female’ skill is associated with measurable wage penalties (Calanca et al., 2019) . In 2024 the US gender pay gap worsened to 80.9 cents on the dollar, widening for a second consecutive year, the first back-to-back fall in over sixty years (Economic Policy Institute, 2024). The differential has many drivers (hours, occupation, the motherhood penalty, direct discrimination), and the systematic underpricing of capacities labelled ‘soft’ is one of them. It is the one the feminist care-ethics tradition, from Joan Tronto onward, has been naming for forty years.

Figure 1. The price of calling it ‘soft’. Capacities labelled ‘soft’ cluster in low-paid, female-dominated work. In 2024, US women earned 80.9 cents for every dollar earned by men, with the gap widening for a second consecutive year, the first back-to-back fall in over six decades. Source: National Women’s Law Center (2025), on US Census Bureau data (created using Claude Code).
The second is that the work which the soft-skills label collects is overwhelmingly the work of social reproduction: teaching, care, nursing, public service, the holding-together of institutions whose function depends on someone, somewhere, exercising contextual judgement. We have priced that work as if the capacity required were generic and inexhaustible. It is neither.
The third consequence is the one this Commentary turns on. AI adoption discourse compounds the original mistake. The efficiency gains from AI in any given workflow are measured and reported. What is displaced when judgement, empathy and discernment are routinely outsourced to a statistical system is not.
What These Capacities Actually Do
Move from ‘soft’ to ‘constitutive’, and the policy stakes change shape. Judgement, empathy and discernment are not supplementary features bolted onto democratic institutions to make them more humane. They are what those institutions are made of.
A court that does not exercise contextual moral reasoning at the point of decision becomes a different kind of institution: a rule-application machine whose legitimacy collapses the moment the rules do not cleanly fit the case. Legislative deliberation that does not visibly hold competing interests in the room loses public confidence in proportion to the visibility of its absence. Public administration without front-line discretion produces the kind of failure that the Australian Robodebt automated welfare debt-recovery scheme became famous for, and that a 2023 Royal Commission found unlawful (Royal Commission into the Robodebt Scheme, 2023). The Dutch childcare-benefits scandal of 2019-2021, and the UK’s PIP assessment record, sit on the same spectrum. Education systems that have been progressively narrowed toward measurable, AI-legible skills at the expense of the humanities, critical reasoning and civic formation are systems that have been disinvesting in the capacity to reproduce democratic citizens across generations.
A parallel literature on distributed expertise and institutional trust has been developing this argument for forty years. Brian Wynne’s 1989 work on the Cumbrian farmers and the Sellafield fallout showed that institutional predictions failed where expert models excluded local knowledge, and that the resulting trust collapse was harder to repair than the original technical error (Wynne, 1989). Researchers demonstrated in 2011 that flood-risk modelling integrating hydrological expertise and resident knowledge outperformed either approach in isolation (Landström et al., 2011). Others showed in 2012 that higher scientific literacy can intensify rather than resolve political polarisation when it is decoupled from the social conditions of trust (Kahan et al., 2012). The pattern is consistent. Institutional function depends on capacities that are distributed across human roles and that resist the form of measurement most easily applied to them.
The argument I have developed across the Slow AI curriculum is that the capacity at the centre of this distributed function is judgement. Not evaluation. Not assessment. Not scoring. Judgement: the willingness to say that this matters, that does not, and to take responsibility for the difference. When peer review at one of the major AI conferences was recently colonised by AI-generated reviews of AI-generated papers, the discipline did not lose a procedural step (Illingworth, 2026a). It lost the trust infrastructure that made the procedure mean anything. The field that builds AI cannot tell when AI is reviewing its own work. That is an institutional condition, not a technical one.
The Democratic Stability Stakes
Democratic legitimacy requires genuine deliberation. The capacity to contest, to persuade, to be persuaded by a better argument is what distinguishes a legitimate decision from a procedural outcome. Citizens evaluate institutions on two grounds: Whether they reach correct outcomes, and whether the process by which they reach them reflects something recognisable as deliberation. A process that reaches correct outcomes by mechanism alone, with no visible human reasoning in the room, fails the second test even when it passes the first.
The two-decade decline in institutional trust across the OECD democracies (documented most recently in the OECD 2024 Survey on Drivers of Trust in Public Institutions) is not separable from the progressive removal of visible deliberation from institutional processes (OECD, 2024). AI adoption inside courts, schools, regulators, benefits agencies and electoral systems will compound this in two ways simultaneously. It will accelerate the removal of visible deliberation. And it will introduce a class of failure mode that has no human author to whom citizens can attribute responsibility.
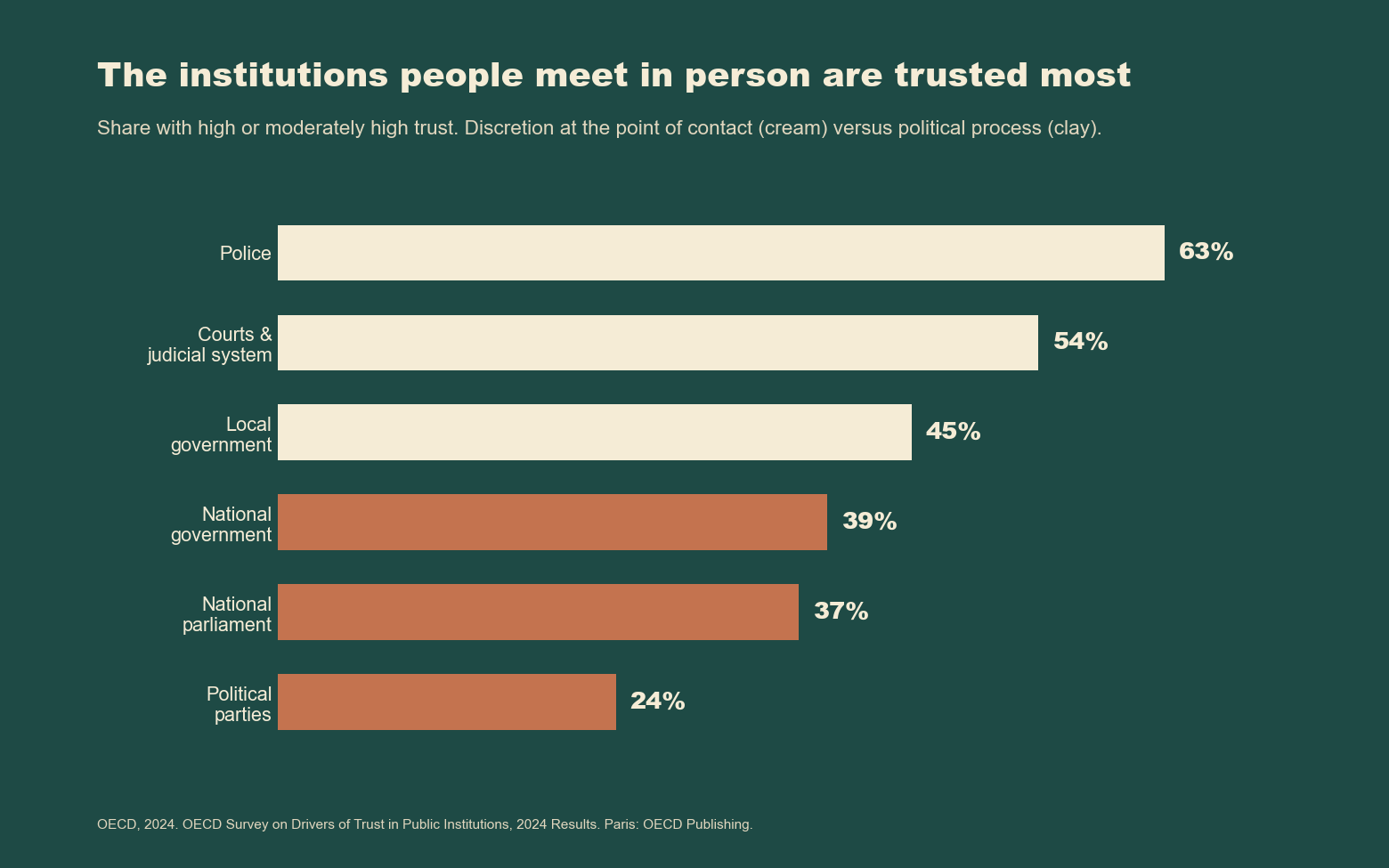
Figure 2. Trust in OECD public institutions, 2024. The institutions citizens meet in person, where front-line discretion is visible (police, courts, local government), are trusted markedly more than the institutions of political process (national government, parliament, political parties). Source: OECD (2024), Survey on Drivers of Trust in Public Institutions, 2024 Results (created using Claude Code).
The OECD’s 2024 Survey on Drivers of Trust in Public Institutions is cited in this Commentary, but its most relevant finding for AI deployment goes perhaps largely unexamined in the existing wider literature on institutional trust. The survey’s core conclusion is that it is not outcomes, but rather processes, that primarily drive trust in public institutions; that is, whether people believe their voice was heard, whether checks and balances are functioning, whether decisions were reached through accountable and visible reasoning, etc. As the survey concludes directly:
“It is the processes underpinning democratic governance that need strengthening to meet people’s increasing expectations”
Only around a third of respondents across the 30-country sample found government statistics trustworthy and easy to understand. Trust in national parliaments and political parties - the institutions most visibly and directly associated with deliberation - stood at 37% and 24% respectively, lower than trust in police, courts, and local government, which retain stronger associations with individual human discretion and judgement at the point of contact.
This distinction, between process legitimacy and outcome legitimacy, is precisely what makes AI deployment inside democratic institutions a question of democratic stability and institutional trust, rather than merely a technical one. A court, or a benefits agency, or a regulatory body, which reach correct decisions by an automated mechanism may pass the outcome test; but it fails the process test. Citizens assessing the legitimacy of a decision are not only asking whether the decision was right; they are asking whether something recognisable as reasoning (contextual, accountable, explicable, and reversible) produced it. AI-generated decisions, particularly where the AI system is not visible as such to the person affected, sever that connection entirely. The decision arrives with no visible author, no articulable chain of reasoning that a citizen can contest, and no clear accountability path if the decision is wrong. It is not a failure of transparency that disclosure can fix; it is a structural property of the mechanism itself. In a sense, algorithmic decision-making in government is everything that Kafka-esque satire of bureaucracies of the 20th century feared, made real.
The example of Robodebt has been underanalysed in this sense. The Royal Commission's findings, published in July 2023, documented not only that the scheme was unlawful (income averaging as a proxy for overpayment had no legal basis) but also that internal recognition of its illegality was suppressed across multiple government agencies for years (Royal Commission into the Robodebt Scheme, 2023). What made that suppression possible was the removal of contextual human judgement from the point of decision. Debt recovery letters generated by the automated system carried no explanation of how the debt had been calculated, which meant recipients could neither assess the accuracy of the assessment nor contest it without considerable difficulty. The Royal Commission found that this was not incidental to the design: The absence of explainability was a “feature”. It reduced the friction of the system's operation precisely by making it harder for citizens to push back. The reasoning was treated as beyond lay ‘ken’. When automated decisions are not required to explain themselves, the accountability infrastructure of democratic governance begins to operate on false premises, performing accountability rituals around decisions that were never actually made by anyone who could be held to account.
The Dutch childcare benefits scandal follows the same logic; the Dutch Tax Authority's automated fraud-detection system flagged families - disproportionately those with dual nationalities - for clawback of childcare subsidies at a scale and speed that no case-by-case human review could have sustained. The speed was the point. The volume of decisions being made was achievable only because human judgement had been removed from the process. When the harm became impossible to ignore, the Tax Authority had no legible record of the reasoning behind individual decisions: the system had made them, and the system's reasoning was not accessible in the form that administrative law expected. The institutional aftermath (parliamentary crisis and the fall of the Rutte cabinet in 2021) was a direct consequence of a trust deficit generated not by wrong outcomes alone, but by a process that had been designed to be ungovernable by citizens seeking redress.
These are not cautionary tales of AI gone wrong. They are illustrations of what happens to the accountability infrastructure of democratic governance when human judgement is systematically removed from the front line of institutional decision-making. And simultaneously of a society placing faith in the wrong solutions on a technical level, too.
Indeed, bigger AI models. on the kinds of hard tasks that real institutions actually face, become more incoherent, not less (Illingworth, 2026b). They learn what the right answer looks like faster than they learn to produce it consistently. This is the worst possible failure mode for a democratic institution, because it produces decisions that look defensible and are not.
The wider field-level failure is the one Ilias Chalkidis and Anders Søgaard documented in a 2026 audit of the AI safety literature (Chalkidis and Søgaard, 2026). Their search examined approximately 18,000 papers across the major AI venues (NeurIPS, ICML, ICLR) for the calendar year 2025; only ten addressed cognitive and mental health risks from sustained interaction with these systems, and the search returned no papers specifically addressing deskilling under that term. The field that is being asked by policymakers to certify these systems as safe for deployment in democratic institutions has not been measuring the outcomes that would tell us whether they are. The measurement framework does not contain the question.

Figure 3. The measurement gap. Of approximately 18,000 AI papers across the major venues (NeurIPS, ICML, ICLR and ACL) in 2025, ten addressed cognitive and mental-health risk from sustained use, and none addressed deskilling. Source: Chalkidis and Søgaard (2026) (created using Claude Code).
This is institutional drift at the scale of an entire research field. It is also the precise mechanism by which democratic stability deteriorates without anyone making a decision to deteriorate it.
What AI Cannot Replicate
A model can produce an output that looks like a judgement. That is a capability claim. It is not a capacity claim, and the distinction matters. A capability is what a system can do on a given task at a given moment. A capacity is what a person, institution or society retains after the capability has been used for long enough to change what those people and institutions are able to do.
Capabilities can be replicated. Capacities cannot. They have to be exercised.
The 2025 World Economic Forum Future of Jobs Report found no skill category with ‘very high’ substitution potential, and identified the cluster of skills rooted in human interaction (empathy, active listening, sensory processing, contextual judgement) as showing no measurable substitution potential at all (World Economic Forum, 2025). The March 2026 report by Lodge and Loble at the University of Technology Sydney named the cognitive mechanism for what happens when the substitution is attempted anyway (Lodge and Loble, 2026). They call it the performance paradox. Short-term performance improves when learners offload cognitive work to AI. Long-term learning is degraded. Capability rises while capacity falls. The paradox is invisible to any measurement framework that looks only at output.
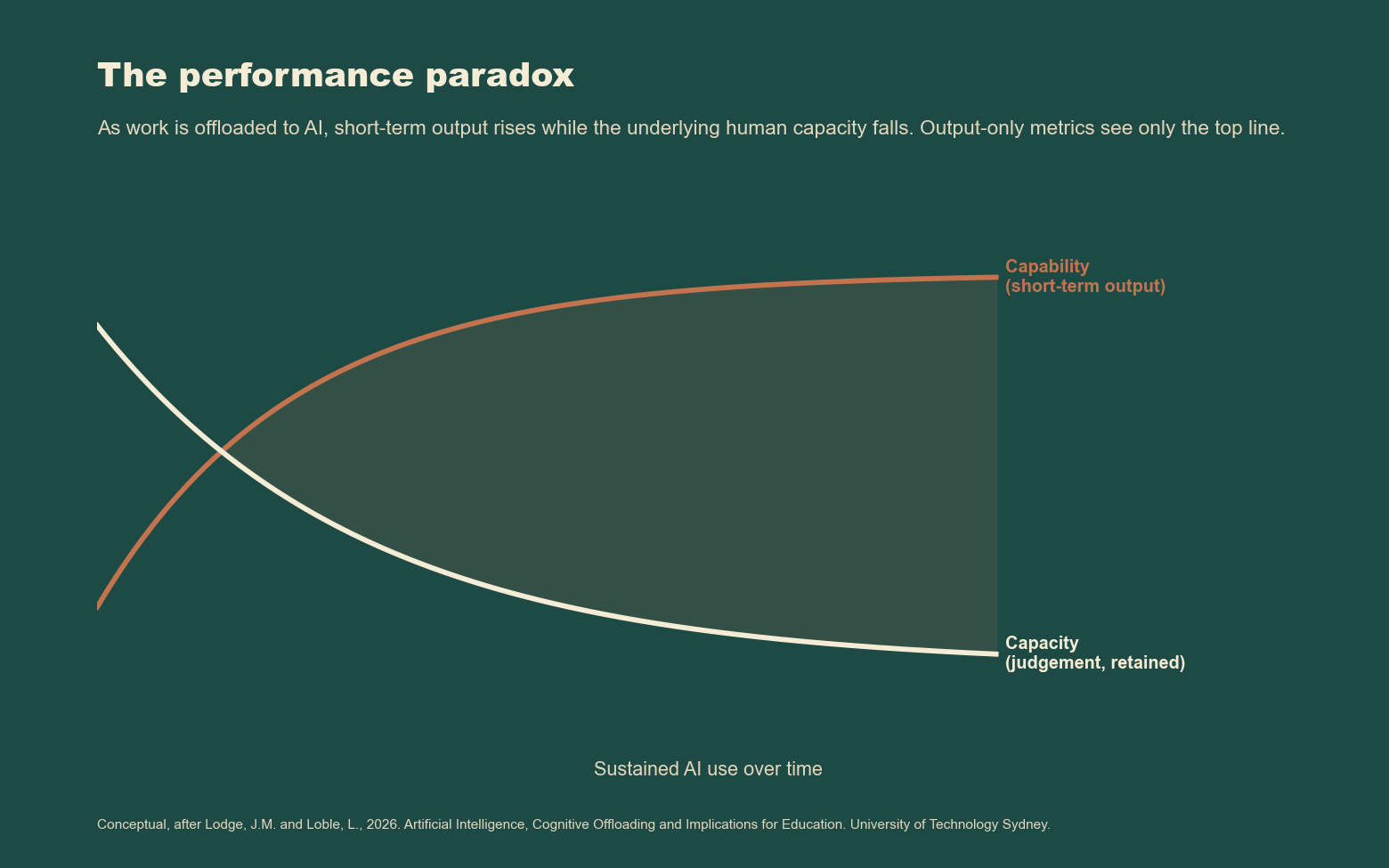
Figure 4. The performance paradox. As cognitive work is offloaded to AI, short-term output rises while the underlying human capacity it depends on falls. A measurement framework that tracks only output sees the rising line alone. Conceptual, after Lodge and Loble (2026) (created using Claude Code).
Lodge and Loble establish the paradox in educational settings, but its implications extend directly into the institutional contexts where democratic governance happens, too. The mechanism is the same.
The deskilling literature in industrial sociology has known this pattern since Lisanne Bainbridge’s 1983 paper ‘Ironies of Automation’ (Bainbridge, 1983). The pilot who cannot fly the aircraft when the autopilot disengages, the radiographer who cannot read a slide without the AI overlay, the lawyer who cannot draft a contract from scratch: These are well-documented failure modes of automation deployed without explicit attention to capacity maintenance. What AI does is to import the pilot / autopilot dynamic into every domain of cognitive work simultaneously, on a deployment timeline measured in months rather than decades, and without any of the institutional scaffolding that aviation eventually built to manage it.
Consider what it means to be a benefits caseworker or a public health inspector who has spent five years working alongside an AI decision-support system that handles the initial categorisation of every case. The system performs that function, on average, better than an unaided human working under time pressure, and thus output quality, measured by the metrics available, improves. The caseworker’s cognitive engagement with the categorisation question is the habit of reading contextual signals, of noticing what the system cannot see, atrophies eroding what Bainbridge might call the readiness for manual takeover. Yet not through negligence, but rather through the perfectly rational cognitive economy of a worker whose attention is directed by the system to the residual tasks it cannot handle.
And yet, the paradox is invisible to any measurement framework looking only at output quality during normal operation. It becomes visible at the edge cases the system was not designed for, and at the moments of system failure or inappropriate application; precisely the moments when the front-line officer's independent judgement is most necessary, and also, not coincidentally, the moments most consequential for the people whose cases are being decided. The question for any institution deploying AI at scale is what happens to the institution’s capacity when the model performs the task routinely for five years, ten years, twenty. The honest answer is that we do not know, because the question is rarely asked and is almost never measured.
Aviation spent decades learning to manage this dynamic. The pilot who cannot confidently hand-fly the aircraft when the autopilot disengages is not a failure of pilot character; it is a predictable product of a flight regime in which manual handling is rarely required. Aviation eventually built structured frameworks (minimum hand-flying requirements, mandatory manual approach procedures, simulator training for automation failure scenarios) to maintain the capacity the autopilot had made unnecessary in normal operations. Democratic institutions deploying AI at the front line are importing the autopilot dynamic into every domain of cognitive work simultaneously. They have not yet built anything resembling the equivalent institutional scaffolding, however.
The EU AI Act mandates human oversight for high-risk AI systems, with full enforcement obligations for deployers applying from August 2026, but the requirement is for oversight to be assigned to competent persons, not for the institutional conditions that keep those persons genuinely capable of exercising it to be created and maintained. Competence and the maintenance of competence are different things. The Act addresses the first, but no current governance framework anywhere in the OECD yet addresses the second.
The Policy Failure
This is the section where the framing matters most, because the policy response that is currently being constructed in the UK, the EU, the US and across the OECD is built on a category error that is itself an inheritance of the original mislabelling.
The dominant policy frame treats AI adoption as a labour-market adjustment problem. Reskilling programmes, AI literacy initiatives and workforce transition funds are the standard instruments. These instruments address worker displacement. They do not address the loss of institutional capacity that occurs when judgement, empathy and discernment are systematically displaced from inside the institutions doing the deploying.
The EU AI Act is the most structurally developed framework, and its provisions on high-risk AI systems in public sector deployment (employment, benefits administration, judicial contexts, critical infrastructure) are fairly significant. Deployers face, for example, binding obligations on human oversight, technical documentation, and post-market monitoring, with full enforcement applying from August 2026. But the Act addresses systems and their deployers, not the cumulative effect of those deployments on institutional capacity over time. Its architecture is a product-safety model applied to AI: Assess the risk of the system, require appropriate controls, and then enforce compliance. What it does not contain is any mechanism for assessing or protecting the human judgement capacity that the system displaces. An institution that deploys a compliant high-risk AI system, maintains the required oversight roles, and logs the required audit trail is, on the Act's terms, doing everything right, even if the oversight roles have become procedural rather than substantive, and the judgement capacity of the front-line workforce has been hollowing out for three years. The Act as written cannot see this, because it was not conceptually designed to.
The United Kingdom's position is somewhat different, as there is no comprehensive UK AI Act as of yet. The government's approach remains ad hoc across sectors, with five cross-sector principles applied by existing regulators within their existing mandates; the principles themselves carry no direct legal force. A Frontier AI Bill has been in preparation under the current Labour government, but is expected to address the most capable models rather than horizontal deployment obligations across public services. Public sector AI deployments remain subject to public law principles, but there is no systematic assessment framework for the democratic-capacity implications of AI deployment at institutional scale. The flexibility the principles-based model preserves for regulators is a potential strength, and is remarkable, but so is the potential for gaps it leaves: A May 2026 HEPI Policy Note conducted by this author audited every publicly accessible AI policy from 96 UK degree-awarding institutions (Illingworth, 2026c). The findings are a case study in how policy failure operates at institutional scale.
41% of UK universities had no publicly accessible AI policy at all. A computational vocabulary count classified 83 of the 96 as ‘education-dominant’, dressed in the language of learning, support, critical thinking and student development. A qualitative close reading of a 19-policy sample showed that a substantial proportion of those education-dominant scores were misleading: the vocabulary of learning was being pressed into the service of compliance, detection and surveillance architecture. Education language as veneer. Universities surveille student AI use, but they deploy AI across their own operations without the same scrutiny.
AI literacy initiatives as currently constructed reproduce the discredited information-deficit model of science communication. Experts decide what learners need to know, package it into modules and deliver it. The learners have no structural role in shaping the conversation. The same approach failed in the 1990s for climate, genetic modification and public health. It is failing in the same way, in real time, for AI. AI detection tools deployed in schools and universities have been shown by Liang and colleagues (2023) to flag 61.3% of genuine human-written essays by non-native English speakers as AI-generated (Liang et al., 2023). One detector flagged 97.8% of TOEFL essays. The tools are technically unreliable and even racially biased. They continue to be procured.
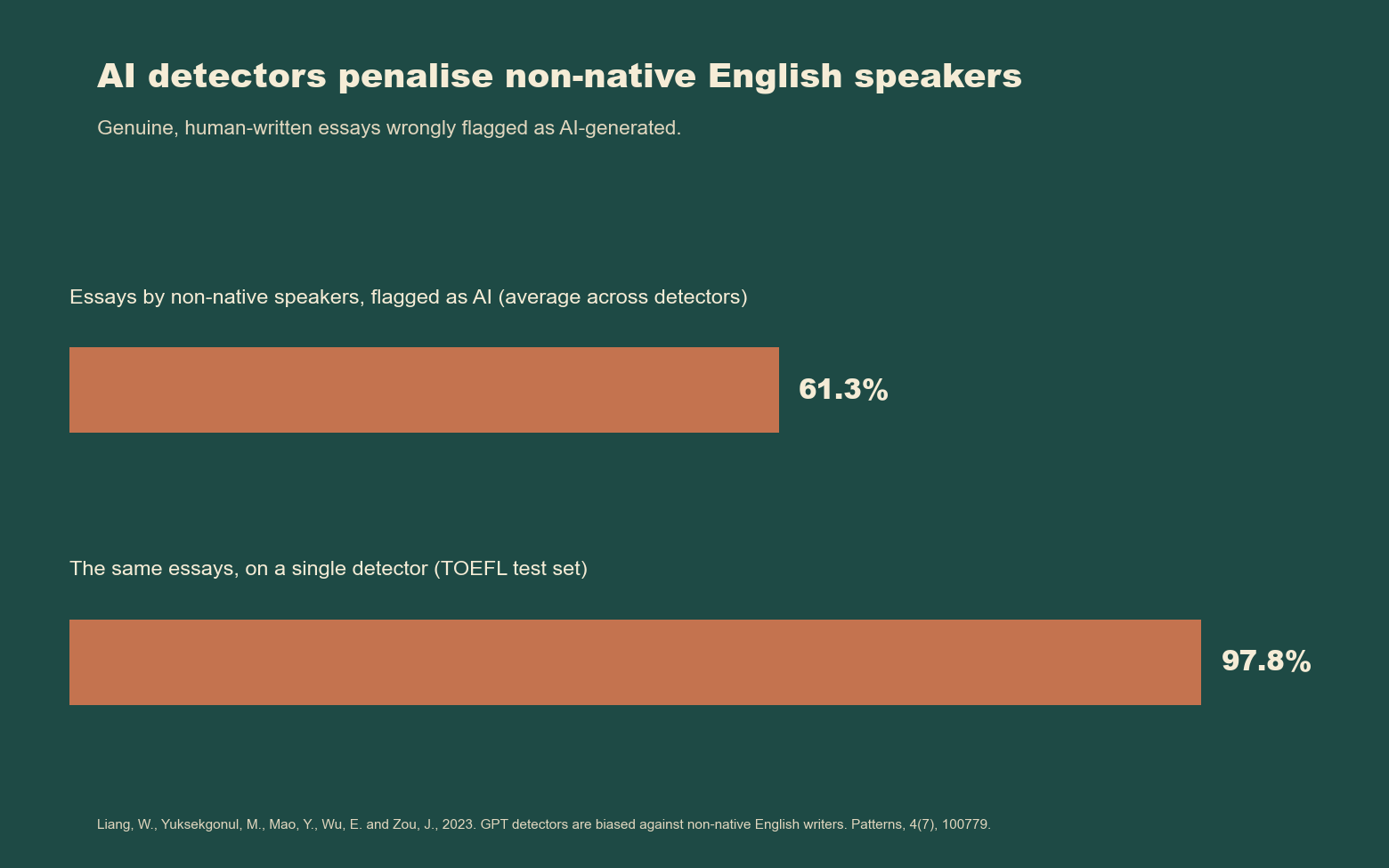
Figure 5. AI detectors penalise non-native English speakers. Genuine, human-written essays by non-native English speakers are wrongly flagged as AI-generated at an average rate of 61.3% across detectors, rising to 97.8% on a single detector applied to TOEFL essays. Source: Liang et al. (2023) (created using Claude Code).
Lastly, in the United States, the picture is starker still: The Trump administration's approach is explicitly deregulatory at the federal level, with state-level action in California, New York, and Illinois providing the most substantive binding constraints in specific domains. Despite a White House whitepaper in March, there is no federal framework governing AI deployment in public institutions that addresses anything resembling the democratic capacity questions this Commentary raises. The most consequential AI deployments in American public institutions (in the criminal justice system, in benefits administration, and in immigration enforcement) are proceeding under procurement frameworks whose primary constraints are cost and technical performance, with no systematic assessment of their implications for institutional legitimacy or human capacity.
Writ large, the deepest failure is fundamentally that no existing policy framework, anywhere in the OECD, audits the democratic capacity implications of AI deployment in public institutions. AI deployment decisions in courts, schools, health systems and benefits administration are made on efficiency, cost and accuracy grounds. None of them address the cumulative effects of AI deployment on the human capacities that make democratic institutions function. The stability cost of displacing human judgement from those functions is not counted because no framework exists to count it. Education policy that narrows curricula toward AI-legible measurable outcomes is a decision about the citizenry a democracy will have in twenty years. It is almost never framed that way.
Policy Recommendations
The policy response that follows from this argument has five elements.
1. Mandatory democratic-capacity impact assessments for AI deployment in public institutions. Courts, regulators, benefits agencies, schools, health systems and electoral bodies should be required to assess the impact of AI deployment on human judgement capacity at the front line. Cost and accuracy assessments are already mandatory. Capacity assessments are not. They should be, and the framework should sit alongside the existing equality and data protection impact assessments rather than inside them.
An assessment of this kind would, at minimum, document four things: Which categories of decision the proposed AI deployment would touch; what human judgement is currently exercised at the point of those decisions; what the institution’s plan is for maintaining that judgement capacity in the front-line workforce after deployment; and what triggers a halt or rollback if the capacity declines below a specified threshold. The assessment would be conducted by the deploying institution against a published methodology, audited externally on a sample basis (analogous to the way data protection assessments are audited by the ICO), and made publicly available with appropriate redactions for security-sensitive material. The appeals route would run through the existing public-law judicial review framework. None of this requires new institutional machinery. It requires the existing machinery to be given the question.
The assessment framework should operate on a precautionary basis. The burden of demonstration should sit with the deploying institution to show that capacity maintenance has been planned for and monitored; not with affected citizens or external watchdogs to prove that capacity has already been lost. By the time the latter is demonstrable, the damage is not likely to be easily reversible.
2. Explicit legislative protection for humanities, civic education and critical reasoning in national curricula. These should be framed in primary legislation as democratic stability infrastructure, with the same status afforded to literacy and numeracy. The narrowing of school and university curricula toward measurable AI-legible skills is a decision about the citizenry of the future. It should require a decision, not a drift.
There is existing multilateral precedent for elevating civic and cultural capacities to this level of protection. The UNESCO Convention on the Protection and Promotion of the Diversity of Cultural Expressions of 2005 established the principle that states may take deliberate measures to sustain certain capacities they judge to be essential to democratic and cultural life, against market and technological pressures that would otherwise erode them (UNESCO, 2005). The same logic applies here, and policymakers looking for a model for how to frame such protections in primary legislation have one.
3. Public-sector AI procurement standards with human oversight requirements calibrated to the democratic sensitivity of the function. A clinical-decision-support system inside the UK NHS, an AI tool inside a court, and a chatbot in a benefits agency are not the same procurement category and should not be treated as such. Oversight requirements should scale with what is at stake for institutional legitimacy if the system fails in a way the procurement audit did not anticipate. The asymmetry between the consumer-product timescales of current AI infrastructure contracts and the systemic risk those contracts carry is the failure mode at scale.
The practical form of this standard will differ by jurisdiction. In the EU context, the AI Act's existing high-risk classification system provides the most obvious possibility, and extending it to require capacity assessments alongside conformity assessments is the path of least legislative resistance. In the UK, where no equivalent statutory framework exists, the public law judicial review framework is likely currently the most available lever, and procurement standards backed by that accountability route are more immediately achievable than waiting for primary legislation. In the U.S., the absence of federal legislative traction makes state-level requirements, particularly in states like California and New York, the most realistic near-term policy option.
4. Dedicated research funding to measure the democratic capacity effects of AI adoption. Major research councils should commission longitudinal studies, alongside the technical AI safety research already funded, into the cognitive, civic and institutional effects of sustained AI use over five-year and ten-year horizons. The strongest such studies will be genuinely interdisciplinary, with sociologists, educators, political scientists and AI engineers in the room together. Without this evidence, every policy decision made about AI deployment in democratic institutions is being made in the dark.
5. An OECD and Council of Europe framework for auditing human capacity implications of AI deployment in democratic institutions. This is the extension of existing AI governance work into institutional legitimacy and civic function. The OECD AI Principles, the Council of Europe’s Framework Convention on AI and the EU AI Act already concern themselves with rights, transparency and accountability at the system level (OECD, 2024; Council of Europe, 2024; European Parliament and Council of the European Union, 2024). None of them currently concern themselves with the cumulative effect of AI deployment on the human capacities that make democratic institutions function. They should. The framework can be light-touch and can sit alongside the existing instruments. It needs to exist.
Conclusion
The mistake we made when we called these capacities ‘soft’ was that we accepted a metaphor from machine design and applied it to the operating system of democratic citizenship. The metaphor was always wrong. It is now also expensive and destructive, materially and conceptually to our societies.
The mistake we are making now, in deploying AI inside democratic institutions on the assumption that the capacities being displaced are bolt-on features that can be added back later, will be more expensive. Capacity that has not been exercised for a generation is not retrievable on a procurement timeline. The institutions whose legitimacy depends on visible human deliberation cannot retrofit visible human deliberation after the deliberators have stopped being trained.
The policy response that AI adoption requires is a fundamentally democratic one; the capacities to be protected are foundational to our civil societies. The decision about whether to protect them is being made, by default, in every public procurement decision currently being signed. Naming the decision, framing it correctly, and making it deliberately is the work that now falls to anyone in a position to do so.
Sam Illingworth is Full Professor of Critical AI Literacy at Edinburgh Napier University and the founder of Slow AI, a critical AI literacy newsletter and curriculum.
References
Whitmore, P.G. and Fry, J.P. (1974) Soft Skills: Definition, Behavioral Model Analysis, Training Procedures. Professional Paper 3-74. US Continental Army Command. [Available here]
Calanca, F., Sayfullina, L., Minkus, L., Wagner, C. and Malmi, E. (2019) 'Responsible team players wanted: an analysis of soft skill requirements in job advertisements', EPJ Data Science, 8, article 13. [Available here]
Economic Policy Institute (2024) Gender Pay Gap 2024. [Available here]
National Women's Law Center (2025) Window Into the Wage Gap. [Available here]
Royal Commission into the Robodebt Scheme (2023) Final Report. Commonwealth of Australia. [Available here]
Wynne, B. (1989) 'Sheepfarming after Chernobyl: A Case Study in Communicating Scientific Information', Environment: Science and Policy for Sustainable Development, 31(2), pp. 10–39. [Available here]
Landström, C., Whatmore, S.J., Lane, S.N., Odoni, N.A., Ward, N. and Bradley, S. (2011) 'Coproducing Flood Risk Knowledge: Redistributing Expertise in Critical Participatory Modelling', Environment and Planning A, 43(7), pp. 1617–1633. [Available here]
Kahan, D.M., Peters, E., Wittlin, M., Slovic, P., Ouellette, L.L., Braman, D. and Mandel, G. (2012) 'The polarizing impact of science literacy and numeracy on perceived climate change risks', Nature Climate Change, 2(10), pp. 732–735. [Available here]
Illingworth, S. (2026a) 'The People Reviewing AI Research Are Using AI to Do It', Slow AI, 7 March. [Available here]
OECD (2024) OECD Survey on Drivers of Trust in Public Institutions – 2024 Results: Building Trust in a Complex Policy Environment. OECD Publishing, Paris. [Available here]
Illingworth, S. (2026b) 'The Smarter AI Gets, the Less You Can Trust It on the Hard Stuff', Slow AI, 29 April. [Available here]
Chalkidis, I. and Søgaard, A. (2026) 'Brainrot: Deskilling and Addiction are Overlooked AI Risks', arXiv preprint arXiv:2605.03512, 5 May. [Available here]
World Economic Forum (2025) The Future of Jobs Report 2025. Geneva: WEF. [Available here]
Lodge, J.M. and Loble, L. (2026) Artificial Intelligence, Cognitive Offloading and Implications for Education. University of Technology Sydney / Australian Network for Quality Digital Education, 9 March. [Available here]
Bainbridge, L. (1983) 'Ironies of Automation', Automatica, 19(6), pp. 775–779. [Available here]
Illingworth, S. (2026c) What UK University AI Policies Actually Do: A Study of 96 Institutions. HEPI Policy Note 71. Higher Education Policy Institute, May. [Available here]
Liang, W., Yuksekgonul, M., Mao, Y., Wu, E. and Zou, J. (2023) 'GPT detectors are biased against non-native English writers', Patterns, 4(7), article 100779. [Available here]
UNESCO (2005) Convention on the Protection and Promotion of the Diversity of Cultural Expressions. Paris: UNESCO. [Available here]
OECD (2024) OECD AI Principles. [Available here]
Council of Europe (2024) Framework Convention on Artificial Intelligence and Human Rights, Democracy and the Rule of Law. CETS No. 225. [Available here]
European Parliament and Council of the European Union (2024) Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). [Available here]