
When Nothing Is Trustworthy: AI, Transparency, and Democracy
By Bennett Iorio (GIEF) and Lukas Lyrestam (Transparent Audio.AI)
Information Disorder
In the last five years, generative AI models have turned realistic audio and video fabrication into a trivially easy capability. For good or - sadly - often for ill, a citizen of any nation across the globe can convincingly create a voice clone or a video deepfake in the space of an afternoon, and the marginal cost of doing so (to varying degrees of fidelity) has fallen towards zero; meanwhile, the cost of verification for institutions has gone in the opposite direction.
Fraud, extortion, political manipulation and personal harassment are all moving with that cost curve. For example, voice cloning is now a standard tool in extortion and manipulation scam handbooks; the US Federal Trade Commission warns that scammers are already using cloned voices of relatives and colleagues to make requests feel urgent and believable, and is treating this as an active enforcement priority (Federal Trade Commission, 2024). The scale of the problem is vast: In aggregate, digital fraud losses reported to US authorities reached between $12.5 and $16 billion in 2024, representing a 25% to 33% increase from 2023 alone (Federal Trade Commission, 2024). The numbers do not tell us how many of those cases involved deepfakes or voice clones, but they do show the direction of travel (See Figure 1).
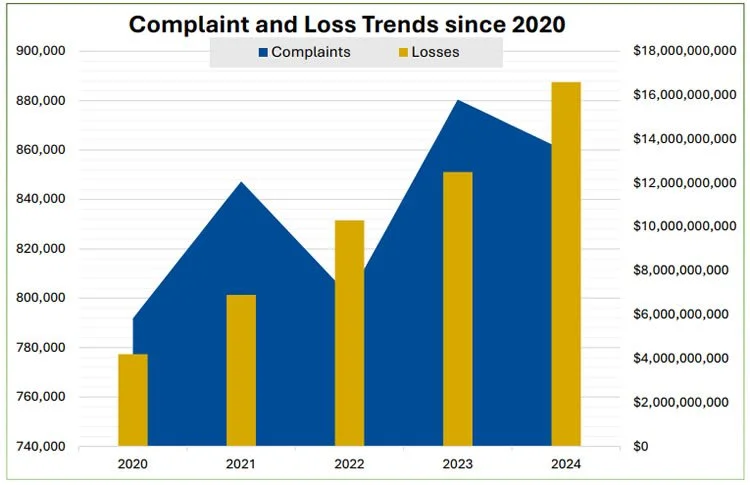
Figure 1: IC3 Complaints and Losses Trend by Year
These harms are ugly, to be sure. The destructive issue lurking behind economic loss figures and the obvious potential for personal harm from fraud is the collapse of institutional and societal trust in information. Democracies depend on shared baselines in order to hold the ‘democratic conversation’; citizens need to be able to treat some classes of evidence, some official communications, and some parts of public discourse as more likely to be genuine than not - or in short, credible. Once people believe that audio and video are routinely fabricated, the entire evidentiary hierarchy softens, and thus doubt is introduced into all aspects of communication.
This is a very serious problem for democratic capacity which depends directly on good faith participation. Deepfakes and other synthetic media stress the good faith baseline in two ways. First, by direct damage: Fraud, synthetic sexual abuse, and political manipulation that is hard to remediate, and the second ordinal, by erosion of total confidence, the so-called “liar’s dividend”, where bad actors exploit the existence of deepfakes to deny real recordings or to dismiss any inconvenient evidence as “fake news” (UNESCO, 2024). This is demonstrable, and effective (See Figure 2).
Figure 2: The Liar’s Dividend (ResearchGate)
Underlying all of this, there is also an economic issue: Intellectual property and copyright systems rely on traceable authorship. When synthetic voices and faces can earn revenue at scale while hiding their provenance, the link between rights, compensation, and creative labor starts to fray. That is not just a problem for artists; it is a problem for any sector that uses licensing, attribution, or brand trust as a basic organizing principle. And in a democratic system with free agency that extends across economic and political lines, collapse of brand trust further erodes overall democratic capacity in a society at large.
Thus, technical transparency standards are therefore an urgent standard for reinforcing the “infrastructure of trust.” Watermarking, metadata, and provenance schemes function as part of the infrastructure of trust. While they do not guarantee honesty, they give institutions and citizens an important tool to distinguish tracked content from material that appears from nowhere.
Having established the context of the risk, the objective of this Commentary is to map and understand the risk landscape, survey the emerging regulatory patchwork, and then ask a narrow question: Where do specific transparency measures actually reduce institutional fragility, and which bottleneck policies are worth fighting for first?
What AI Fakes Do to Society
AI fakes have the potential - and are already - harming society and the stability and social contract of our democracies in various ways. The first cluster of harms are financial fraud and the loss of trust in the system that results. Corporate finance teams are now dealing with deepfake conference calls and synthetic “CFO” or “CEO” voices that authorize urgent transfers. Voice cloning enhances existing business email compromise and invoice scams, and makes them more convincing. As mentioned above, the FBI’s Internet Crime Complaint Center recorded more than $16 billion in reported internet-crime losses in 2024 (FBI, 2024), with business-email compromise and confidence scams among the highest-loss categories. Law-enforcement casework and industry analyses describe a clear increase in voice-clone incidents within these broader categories, and digital fraud safety company Deepstrike gives $40 billion as a potential loss figure due to deepfake scams by 2027 (Deepstrike, 2025).
Political harms form the second cluster of harms, which drive disengagement and disillusionment with civil society and democracy. For example, in the run-up to the 2023 elections in Slovakia, an AI-generated audio recording appeared online in which the leader of Progressive Slovakia and a journalist seemed to discuss rigging the vote. It was a fabricated conversation, but it circulated in the last days of the campaign, in an environment already thick with disinformation (Misinformation Review, 2023). Similar deepfake clips have now emerged in nearly all major elections since the start of this century’s third decade, including in Nigeria (Okezie et al, 2025), Pakistan (AI Incident Database, 2024), the United States (Philp 2024), India (Dhanuraj 2024), and the UK (Stockwell et al, 2024). And yet, unlike the propaganda of ages past, these AI artefacts do not need a long half-life or to stand up to close scrutiny; it is enough that they stand up to passing scrutiny (see Figure 3), and if they create doubt, mobilize anger, and ultimately suppress turnout or sway opinions in a narrow window - on an election day, for example - then their purpose has been achieved.
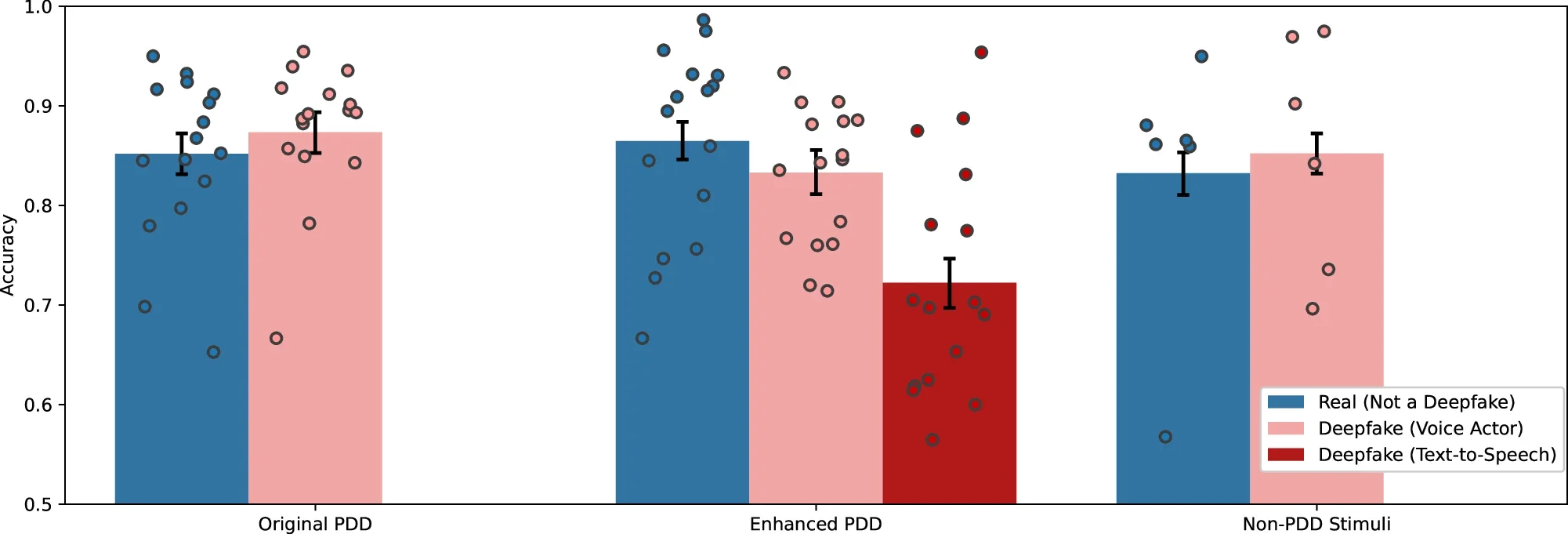
Figure 3: Accuracy Distinguishing Real and Fabricated Speeches Across Video Stimuli, Groh et al 2024.
How to read this chart: Accuracy across the original Presidential Deepfakes Dataset (PDD) video stimuli in Experiment 1a (N = 2228 observations), the enhanced PDD video stimuli in Experiment 2 (N = 3580 observations), and the non-PDD video stimuli in Experiment 2 (N = 2384 observations). The error bars represent 95% confidence intervals. Dot plots represent the mean accuracy for each video stimulus.
A third area of degradation of trust and outright harm is IP and copyright. Synthetic “artists” and cloned voices are already producing videos, music and content that generates advertising and subscription revenue - note, for example, the controversy over “fake artists” on Spotify, where algorithmically generated or minimally attributed music was reportedly promoted within the platform’s ecosystem, illustrates how synthetic or semi-synthetic content can be monetised at scale while blurring authorship and accountability (Lopatto, 2024). Provenance is often unclear - and deliberately so - and it is difficult for rights-holders to detect or prove that their voice or style has been used without consent. The result is a gradual dilution of the link between creative work and compensation, with courts and regulators racing to catch up. Taken to its logical conclusion, the issue leads to destruction of the basic link between creative output and engagement in society, meaning society’s current model of social, economic and political reward for positive contribution collapses. This in turn could ultimately drive higher disengagement from civic society.
These sorts of scams are proliferating into direct consumer attacks, too. The familiar pattern is a call from a distressed child, spouse, or friend apparently in danger or distress and in need of immediate funds. The FTC’s 2024 guidance for consumers does not yet attach a precise loss figure to these calls, but it explicitly identifies voice cloning as a key driver of new fraud patterns and urges banks and telecoms to adapt (FTC 2024). The key point here is that these types of scams strike at a core pillar of trust; they have a high emotional impact and exploit the relationships that people find hardest to need to “verify”.
These personal and societal harms are now widely documented. One of the clearest quantitative accounts comes from a 2024 survey of more than 16,000 respondents in 10 countries, which found that 2.2 percent reported being victims of non-consensual deepfake pornography and 1.8 percent admitted to some form of perpetration (Umbach et al, 2024). These are global averages, and the underlying distribution is almost certainly skewed by gender and age, but the headline is already serious. Recent reporting from schools in the UK and Australia shows deepfake sexual images of classmates being generated and shared among teenagers, with severe psychological effects (The Guardian, 2025).
The point, and the problem, is that each of these harms can scale cheaply. Once a model exists, the marginal cost of another clip is negligible, and the main constraint becomes the friction of distribution and the effort required for verification. That asymmetry in short means that the capacity for AI-generated fake content is vast, and verifying it takes longer and is more difficult than producing it - a concept now popularly known as Brandolini’s Law (Brandolini, 2014)(Thatcher et al, 2018). This is exactly what institutions are not set up to handle. Mark Twain’s adage that “a lie can get halfway around the world before the truth laces up its boots” has never been more true.
The Liar’s Dividend
As deepfake incidents accumulate, awareness of the existence and potential of deepfakes spreads. People learn that audio and video can be fabricated, and that news stories about AI scams are now routine. This learning process has a second-order effect: Genuine recordings become easier to deny.
This is the “liar’s dividend”. In short, a politician caught on tape has a ready-made defence, or a corporate executive can dismiss embarrassing material as synthetic. Courts, regulatory bodies, and journalists are then left to untangle the mess, and it becomes increasingly difficult to decide which ‘truthful’ narrative to believe. The UNESCO case study focuses on the Slovak case precisely to illustrate this problem: When citizens cannot be sure whether a recording is real, disinformation and counter-claims feed on each other.
For courts and the judiciary, the impact is practical and measurable: Audio and video evidence now require more technical scrutiny, more expert input, deeper expert capability, and more time. Evidentiary hearings thus lengthen, with resultant rising costs, and judges and juries have to weigh the credibility of forensic methods they likely do not fully understand. This is directly relevant to stability in our democracies, because a fair legal system based on the idea of evidence representing truth is a cornerstone of every democratic society.
Media organizations face a similar burden. Verification desks must handle more synthetic content, and must do so on tighter timelines. A slow, careful investigation may be correct but irrelevant if the story has already played its political role, and corrections in the media do not make ‘breaking news’ headlines in the same way as outlandish claims. In the study “The Spread of True and False News Online” by researchers at MIT Media Lab (2018), false news spreads significantly farther, faster, deeper, and more broadly than true news. Specifically, false stories were “70% more likely to be retweeted than true stories,” and true stories took about six times as long to reach 1,500 people compared with false ones (MIT Media Lab, 2018).
A related and conflated issue is that it is psychologically well-understood that “outrage” and emotive content is more engaging than neutral and careful content. Social media is frequently cited with regards to this issue, but even traditional media is not immune from the market pressures to compete with ever-more-engaging headlines. Study after study has found that “extreme emotions” are more engaging to readers and viewers (MDPI, 2024).
While AI-generated fake imagery is not at all the originator of outrage or sensationalist media coverage, it is now easier to generate convincing media on outrageous topics. Where previously “yellow journalism” claims could be verified and dismissed relatively easily, both the proliferation and the generated supporting evidence now make combatting this disinformation more costly, more technically difficult, and more time-consuming.
In short, at the level of society, the issue is that everything may or may not be faked, and it is now increasingly difficult for an average citizen to determine. Survey experiments on deepfakes and trust show that exposure to information about synthetic media increases scepticism toward authentic footage and decreases confidence in media generally. This is where stability enters the picture: Institutions that cannot establish what actually happened lose their ability to anchor public narratives, and politics shifts onto terrain where societal debates are determined using faked evidence, or indeed claiming true evidence to be fake. AI Generated voices seem to be particularly hard for the public to discern, with a recent study from Stanford observing that up to 80% of subjects presented with a sample of real and cloned voices couldn’t discern between a real and an AI generated phone call (Barrington et al, 2025).
What is urgently needed to combat this trend is a conceptual standard toolkit of scaleable, effective, understandable and trusted ways to identify fake information and generated content - and the regulation from governments to ensure it is utilized.
Regulatory Momentum
The EU has moved furthest toward a general framework. The EU’s AI Act includes explicit transparency obligations for certain systems, including generative models and deepfakes. Article 50 requires providers to ensure that users are aware when they are interacting with AI systems or exposed to content that has been artificially generated or manipulated, with narrow exceptions for areas such as law enforcement and satire (European Union, 2025). The Act also anticipates harmonized technical standards, to be developed by European standards bodies, which will effectively determine how provenance and labelling happen in practice.
The United States has no single federal law that governs synthetic media labelling. Instead, there is a mix of executive branch guidance, sectoral rules, and voluntary commitments from industry. At state level, however, deepfake laws are proliferating - an encouraging sign, though incomplete. In 2024, California’s governor Gavin Newsom signed a package of bills targeting deceptive AI content in election campaigns. One of them, the “Defending Democracy from Deepfake Deception Act”, requires large online platforms to block or label materially deceptive election-related deepfakes in defined windows around state elections (California State Government, 2025). Texas and New York have passed or proposed election-specific deepfake rules of their own.
The UK sits most deepfake issues under its Online Safety Act, enforced by Ofcom, and has signalled interest in provenance tools as part of broader online harms regulation, though without the level of detail found in the EU package. Internationally, G7, OECD, and Council of Europe processes all talk about transparency in their AI principles, but the language remains high level (Government of the United Kingdom, 2025).
The Chinese government has taken some steps in the direction of regulation: Recent “Methods for the Administration of Generative AI” and related synthetic content rules require providers to include explicit and implicit labels in AI-generated text, images, audio, and video so that users can identify synthetic material (Government of the People’s Republic of China, 2025). This is a more centralized, top-down approach, and we are yet to see the efficacy of this regulation, but it provides early evidence of what mandatory labelling may look like in practice.
Technical Tools
All government regulation is, however, fundamentally dependent on the tools used to enforce the policy. In this context, on the technical side, several families of tools compete for attention. The most common are metadata, AI detection, fingerprinting and watermarking, which are currently in discussion as part of the EU AI Act legislation.
Metadata and provenance schemes are the most technically straightforward because of their text-based and “attached” format. A manifest comes attached to any single file with functionally unlimited fields for users who seek to know where a file came from.
The Coalition for Content Provenance and Authenticity (C2PA), a highly laudable effort founded by Adobe, Microsoft, the BBC, and others, is developing an open standard that attaches a tamper-evident record to images, video, and audio (C2PA, 2025). These “content credentials” can record who created the file, what edits were made, and by which tools. The model here is like a chain of custody rather than a hidden flag in the pixels. The weakness is adoption; however, as provenance is only useful if a critical mass of devices, platforms, and tools agree to read and respect the standard (Tech Policy Press, 2025) (see Figure 4 & 5). A concern raised by C2PA is that even minimal provenance overheads introduce friction into high-volume, real-time content ecosystems, creating systemic resistance to universal implementation, particularly in contexts where speed, scale, and seamlessness are central to how information is produced and consumed. This introduces a tension between regulation standards and business practice.
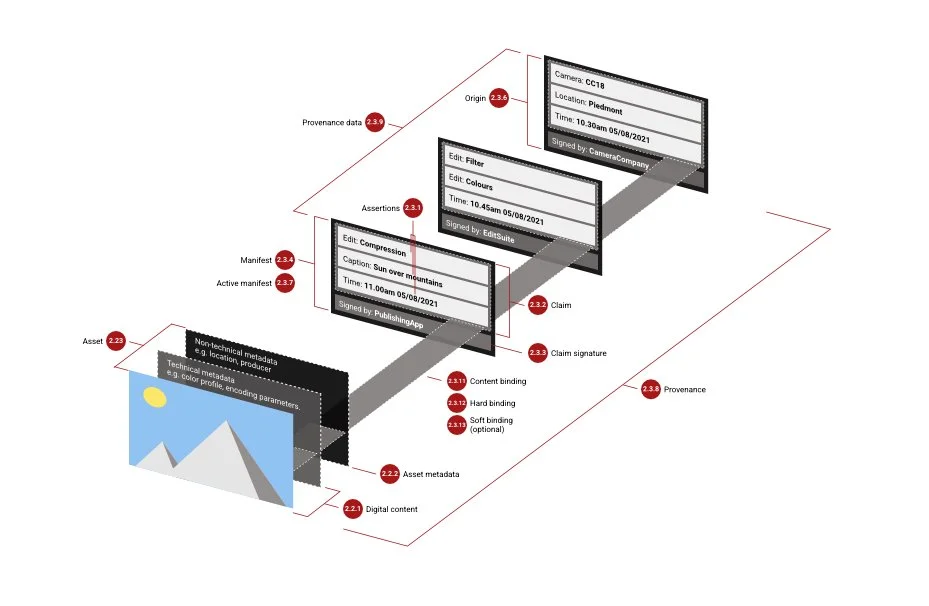
Figure 4: C2PA Architecture
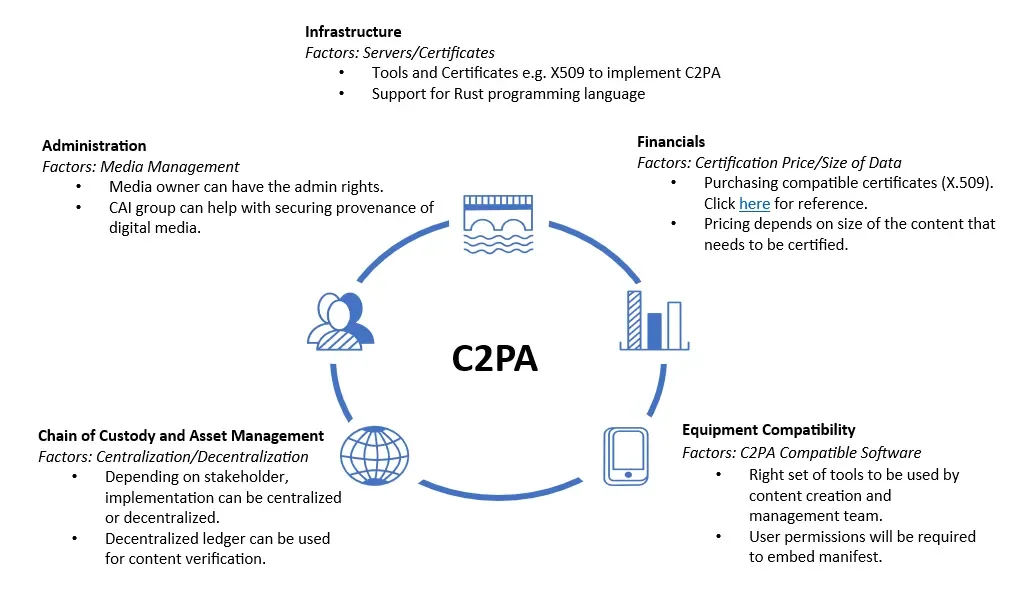
Figure 5: C2PA Utility Cycle
Detection systems, on the other hand, treat deepfake identification as essentially a forensic problem. They analyze a given clip and output a probability (%) that it is synthetic, often by exploiting artefacts left by specific generation models - picking up on ‘tells’. These tools can be valuable for law enforcement and platforms, but they suffer from all the usual classification problems of any probability-based forensic tool: False positives, false negatives, and degradation of veracity when models or domains change. Essentially, detection systems are caught in an arms race, as new generators, LLMs, synthetic artists et c. are trained to evade them, with effectiveness constrained by the availability and representativeness of training data.
Fingerprinting, another technique, arises from existing music-recognition systems (Cano and Battle, 2025). An original audio file is analysed to create a compact “fingerprint” that captures stable characteristics of the signal, and that fingerprint is then stored in a ledger. If a suspect/suspicious clip appears later, it can be compared to the ledger to see whether it matches a known original. This perceptual hash-based digital fingerprinting approach is highly robust to many transformations and is widely used, but it is expensive to operate at the scale of global content production uniformly (Chen et al, 2025). The rate at which fingerprints are created and registered would need to match, or at least closely track, the rate at which new material appears, which presents its own problems of affordability and scale.
Watermarking embeds information within the audio or video signal. The mark may be invisible to the human eye or ear, but machine-readable. In principle, a platform or regulator can check whether a piece of content carries a watermark that signals “generated by System X”. In practice, robustness varies. Heavy compression, re-recording, and deliberate attacks can degrade or remove many watermark schemes, particularly for audio where codecs reshape the signal aggressively.
For further context, as an example, almost every file that is uploaded to platforms like Youtube, Spotify or any other type of DSP (Digital Service Provider) uses heavy compression algorithms - called Codes - to reduce size and improve performance for the end user, hopefully without reducing the quality of any content that is streamed at a later date. The converse of this process is that any watermarks (and metadata manifests) that are present in the file become removed by the algorithm as "unnecessary" information. A recent study at Music Technology Group Barcelona as conducted by Sony AI concludes that almost no existing watermark techniques can survive the standard codecs of the modern information ecosystem (Ozer et al, 2025).
The field of watermarking is complex and already technically advanced, with many different types and techniques existing with various forms and rates of adoption. One of the most commonly identified promising techniques, as pioneered by Google, is SynthID which uses an AI to embed an identifier that, according to company claims, only another AI could decipher. Early experiments show strong robustness and the ability to survive Codec compression but this technology is currently only available for Google products. However the company doesn’t reveal its workings nor provide open-source examples for other Generative AI companies to utilise. This leads us to another thorny subject relating to the interoperability of any technical standards to be adopted.
Each of these technological solutions for identifying the origins of a file have pros and cons to be leveraged, but the larger issue stems from the fact that many different industries use different standards and a general lack of interoperability exists across both mediums and sectors.
Also important to understand, larger corporations dictate technical standards that serve their purpose and are hesitant to share their inner-workings with regulators or competitors. They often drive adoption simply by the size of their product, as opposed to the information requirements that the public deserves to know. Spotify, for example, communicates key information around the composition, source and right attributed to any single music audio file using a metadata standard called DDEX (a non-profit organisation), while C2PA as a candidate for a metadata standard doesn’t support this particular format.
It will take time to integrate an ‘audio medium standard’ into what more traditionally has been focused on image provenance. It’s just one example of the many, many different technical solutions integrated into a variety of industries that will need handholding, grandfathering and guidance for solving the identification of AI generated content.
Technological standards across the same medium aren’t so different, but getting industry stakeholders to spend time and money adapting a single format takes time, diplomacy and co-ordinated effort. Without the buy-in of industry, regulators will have to keep track and regulate a rotating cast of different standards, difficult to police and hard to recommend as best practice as a variety of actors.
The final and perhaps most important point to consider, is the fact that all of these technologies are flawed and only in-conjunction do they provide the most robust authentication. Extensive research by companies like Deepmark and public “Hack my mark” competitions have shown that a determined individual can remove almost all types of content-marking initiatives. This presents a particular challenge for governments facing well-funded, technically savvy and potentially geographically adversarial parties determined to disrupt democratic discourse. Only in conjunction with each other can these technologies provide the best-in-class solution.
Indeed, on a wider level and across all of these tools, policymakers face a simple yet non-trivial question - what works at scale, with realistic constraints on cost, adoption, and evasion. Any serious transparency agenda has to start from that point.
Transparency Could Be the Infrastructure for Democratic Stability
Transparency tools and even companies like Which? are often presented as consumer information aids, and they are valuable in this context, of course. But on the meta level in the frame of stability in our democracies, they must become something more structural: They must help maintain the chain between facts, institutional judgments, and public recognition - in other words, the “democratic conversation”.
In the example of elections, if political ads, official campaign videos, and candidate communications carry standardized provenance information (the requirement, for example, to have a verified watermark of authenticity), electoral commissions and newsrooms can quickly verify whether a suspicious clip comes from a recognized and verified channel or from an anonymous source. When a fabricated audio file appears two days before a vote, as for example in Slovakia, the difference between a rapid, authoritative debunk and a week of confusion can matter enormously for voter turnout and acceptance of results. Provenance tools shift the burden of proof - provided ample education about their rollout (Buttle and Parokkil, 2025). As shown above, deepfakes and AI-generated political content are not isolated incidents; they are being rolled out everywhere by mal-actors, with increasing sophistication and frequency (see Figure 6).

Figure 6: Confirmed Use of Deepfake Technology in National Elections as of July 2025
Nota bene: It is highly important to recognize when reading this map that many of the countries in gray, denoting ‘no confirmed cases of deepfakes’, have not held national elections within the past three years. It is likely that elections held in these countries in future will see deepfake usage in line with those that have held elections recently.
In the financial system, if internal voice agents, video-conferencing systems, and high-value authorization channels use watermarking or provenance tools/schemes that are difficult to spoof, then banks and regulators have a clearer path to attribution. Fraudsters will still try, but the success rate falls and systemic contagion becomes less likely. This is obvious, but not yet universally accepted, and the lack of standardization of systems benefits mal-actors.
Judicial systems also need a way to separate “tracked” evidence from material of unknown origin. Provenance standards for law-enforcement bodycams, forensic recordings, and digital evidence submissions would give courts a higher-confidence subset of media, and judges could then treat recordings with established chains of custody differently from clips with no verifiable history. That would not solve every evidential dispute, but it would stop “everything is fake” becoming a default defence strategy, and limit its efficacy.
Media and the wider information ecosystem would benefit when reputable outlets and platforms display visible provenance indicators. A small icon or label that signals “this video carries a verified content-credentials record” lets audiences sort content into categories of traceable, and untraceable (or explicitly synthetic, which will become increasingly frequent, too). This should not be framed as a binary distinction, however, between “real” and “fake,” but as a graduated spectrum of verification, closer to an energy-efficiency rating than a truth stamp. At the highest level, content might be triangulated through multiple authenticated sources and cryptographic records; at lower levels, it may rely on a single verified origin or partial chain of custody; at the lowest, it may carry no verifiable provenance at all.Not everyone will pay attention, but again with good public education on provenance tools, this will be a clear mechanism to reinforce trust in the information system and to influence the overall tone of public debate.
In each of these, the effect of transparency is to reduce some of the ambiguity that adversaries currently exploit; in a sense, it trims the worst tails of the risk distribution, and this has a positive effect on stability.
Limits of Transparency
It is worth noting that mal-actors will always use increasingly sophisticated methods to attempt to counter the above transparency/provenance tools. They’ll avoid regulated tools and strip metadata whenever they can; that is predictable behaviour. Also candidly true is that human psychology does not disappear when labels arrive, and people who want to believe a convenient fake will often do so (Pohl et al, 2012), provenance or not. People who want to disbelieve an inconvenient truth will find reasons to cast doubt on the label itself; a problem as old as society itself.
Indeed, political capture is also likely in some cases: States could use provenance requirements as a pretext to block dissident content or to require invasive registration for certain kinds of speech (OECD, 2024). However, transparency tools themselves are not necessarily useful - they too carry assumptions from developers, requirements of business models, and definitions of what ‘fake’ means - no easy task. So too is their use bound by all of the motivations of those who always use tools. Thus the need for strong democratic institutions - and good policy - to govern these tools and systems in a responsible way.
And another clear limit is capacity. Tracking every piece of training data used in large models is currently beyond the capabilities of most companies, and although research on dataset tracing and watermarking of training content is evolving, it is also currently true that downstream copyright issues will also remain unsolved in bulk. It is worth noting that some emerging forensic methods can probabilistically detect which large language model produced a given output, but these techniques remain fragile and contestable. Under the current status quo of closed models, robust attribution is structurally difficult; however, this is not a technological inevitability. Regulators could require model providers to disclose structured training-data information or to provide APIs that allow independent tools to verify whether specific content originated from their systems. For example, generative music experts suggest that AI has been generating a minimum of 10 millions songs a month, which gives an idea of the scale of generation that exists across all of Generative AI. Transparency solutions have to be directly correlated with the practical restrictions of the scale of generation.
Lastly, good regulation must work with both AI companies and media/distribution/information platforms, because provenance standard interoperability will be decisive. If a provenance standard exists on paper but the major distribution platforms do not surface it to users, or all use different ones with different fundamental logics, then its stabilizing effect will surely be blunted (RAND Corporation, 2025).
But even with these limits, partial adoption matters. A world where some classes of content are reliably traced, some institutional channels are clearly signed, and some evidence streams are better protected is already more stable than a world where everything floats free and doubt can be cast on any media; at current, our trend indicates degradation of public perception of reliability, and there may be a point of no return. But societal stability is rarely about silver bullets. It is about marginal reductions in fragility and more predictable failure modes, as well as consistent self-correcting and review.
Leverage Points
A global minimum standard for provenance in “critical communications” would thus create a high-trust content “spine” running through the system. State institutions, election authorities, central banks, and major public broadcasters could for example be required to sign their audio and video with cryptographic credentials that follow open specifications, and this would mean that verification tools could then be built into browsers, apps, and broadcast systems. Such integration would not be straightforward: Deploying interoperable standards across thousands of companies, sectors, and legacy systems is technically and institutionally demanding, and the persistence of outdated infrastructure complicates universal adoption. Nonetheless, articulating a common baseline remains valuable, because even partial and phased implementation can materially improve traceability and reduce systemic ambiguity.
Also, standardized transparency requirements for large generative audio and video platforms would move current voluntary commitments into enforceable obligations (China is trialling this). Thresholds could be set by user base, or by revenue, company, or other groups. Above those thresholds, providers would have to embed robust watermarking or provenance and expose verification interfaces to third parties. This could in effect force a convergence around solutions that work across borders - that is, a global compact of companies that create a system beyond the bounds of a single country or entity’s regulatory framework and policy.
Financial regulators and central banks would clearly also need to issue guidance on labelling for voice agents and internal communications in the banking sector, and electoral commissions and campaign-finance authorities would have to incorporate transparency requirements into existing rules on political advertising and campaign materials. Justice ministries/judiciaries and court systems would have to define provenance rules for evidentiary media and invest in tools to validate them.
Alongside technical standards, accountability mechanisms would be essential. Political advertising and paid influence campaigns should be traceable to a verified legal entity, with clear “follow-the-money” requirements that link content to funding sources. Platforms could be required to demonetise undisclosed political propaganda and apply proportionate identity-verification standards for accounts engaged in high-reach or election-sensitive communications. Independent supervisory authorities, with the power to audit and fine for non-compliance, would provide the enforcement backbone. There is precedent for this approach in areas such as regulated financial advice, where disclosure requirements and liability frameworks meaningfully shape behaviour; the informational stakes in democratic processes are at least as significant.
Who Sets the Rules?
Technical standards are never just technical; they are levers of control, and both political and business entities may seek that control. For example, if a small group of firms (for example, the tech giants like Apple, Adobe, Google and Meta) effectively control all provenance tools, they also control the conditions under which others can claim authenticity. That is why political and societal governance of standards matters. Multi-stakeholder processes are messy and slow, but they reduce the risk that a content-credentials system becomes an extension of one company’s product strategy, or a lever by which they can extend control. Governments, independent researchers, civil-society organisations, smaller developers and companies, and rights-holder groups all have distinct knowledge and voices about where these systems can fail or be abused. Open-source products are highly important in this field, whether developed by larger technology organisations or, more often, through citizen-volunteer efforts. They can be publicly used, scrutinized and appropriated by organizations of all sizes without having to worry about IP or cost.
An obvious point to counter state or company capture of these tools once a framework is in place is that interoperability/open specifications should be non-negotiable. Whatever watermarking or provenance schemes emerge, verification should not depend on a proprietary silo. A newsroom in Nairobi should be able to check a clip signed in Brussels without negotiating a separate license, with the same tools.
Open-source advocates building transparent fingerprinting or provenance tools can demonstrate what robustly inspectable systems look like and can stress-test vendor claims. They can also act as translators between policy communities and engineering teams, who often talk past each other, due to the technical nature of the tools involved. Some efforts in this direction are already in place, available open-source on Github specifically for this reason, balancing the needs of transparency with less technical overhead than C2PA. The collaborative nature of open-source tools and communities often lends itself to the principles espoused by a multi-cultural and democratic society while avoiding the pitfalls of only developing for a bottom line.
Policy Recommendations
For national governments and regulators:
Evaluate the need for provenance tool usage in critical state communications and electoral materials, including a clear, open specification and funding for implementation, as part of a wider solution.
Citizen education around these tools to ensure populace awareness of these efforts and what to look for.
Create regulation working groups and grant schemes for transparency tools, with independent testing of watermarking, provenance, and detection performance.
Align financial and cyber regulators around standards for voice-clone and deepfake fraud, treating these as systemic risks to the economic and political system rather than crime or isolated scams.
For regional and international bodies:
Integrate minimum provenance and labelling requirements into AI governance frameworks like the EU AI Act and related G7, OECD etc acts and instruments.
Create a neutral standards body or consortium attached to the OECD, UN or other international body, where governments, firms, and independent researchers can work on transparency specifications that are not vendor-controlled.
Here are the two lines written in the same style and register as the rest of the section:
Establish clear accountability frameworks with designated supervisory authorities empowered to audit compliance, impose fines, and require corrective action where transparency standards are ignored or circumvented.
Introduce traceability requirements for political advertising and high-reach influence content, ensuring that funding sources, sponsoring entities, and monetisation pathways are disclosed and auditable across platforms.
For media platforms and AI companies:
Provide a point of access to verify if AI-generated content is likely to be produced by them.
Commit to open, verifiable transparency mechanisms, and to publishing technical details sufficient for independent verification.
Participate in regular audits of robustness, evasion risk, and real-world performance, with summaries available to regulators and the public.
For civil society and research:
Maintain open datasets and benchmarks for evaluating watermarking, provenance, and detection systems, so that policy debates are grounded in evidence rather than claims.
Conflict of Interest Statement
GIE Foundation produced this Commentary in collaboration with Transparent Audio.AI, a company developing algorithms to detect AI in and watermark audio content. Transparent Audio.AI provided expert technological and market insights on the subject. No money was exchanged between the organizations, and GIE Foundation maintains complete editorial control of all Commentary content. The text reflects the organization's views on this topic, and both organizations agreed on the final version of this document.
Images
Figure 1: IC3 Complaints and Losses Trend by Year - Federal Bureau of Investigation IC3, 2024. Internet Crime Report 2024. [Available here]
Figure 2: The Liar's Dividend - American Political Science Association, 2024. The Liar's Dividend: Can Politicians Claim Misinformation to Evade Accountability? [Available here]
Figure 3: Accuracy Distinguishing Real and Fabricated Speeches Across Video Stimuli - Groh, M. et al 2024. Human detection of political speech deepfakes across transcripts, audio, and video. Nature Communications. [Available here]
Figure 4: Elements of C2PA - Coalition for Content Provenance and Authenticity, 2025. [Available here]
Figure 5: C2PA Utility Cycle - Coalition for Content Provenance and Authenticity, 2025. [Available here]
Figure 6: Confirmed Use of Deepfake Technology in National Elections as of July 2025 - Surfshark, 2025. Election-related deepfakes: global reach and impact. [Available here]
References
Fighting Back Against Harmful Voice Cloning, FTC, 2024. [Available here]
Top Scams of 2024, FTC, 2024. [Available here]
Case Study: Can We Believe What We Hear?, UNESCO, 2024. [Available here]
Annual Crime Report 2024, Federal Bureau of Investigation, 2024. [Available here]
Vishing Statistics 2025, Deepstrike, 2025. [Available here]
AI, Democracy and the Slovak Case, Misinformation Review, 2023. [Available here]
AI In Nigerian Elections: Tool for Safeguarding Democracy or Weapon for Deepfakes and Disinformation, Okezie et al, 2025. [Available here]
Many Purported Political Deepfakes Reportedly Circulating in Run-up to 2024 Pakistani General Elections, AI Incident Database, 2024. [Available here]
How to Identify and Investigate AI Audio Deepfakes, a Major 2024 Election Threat, Philp, 2024. [Available here]
Generative AI and its Influence on the Indian 2024 General Elections, Dhanuraj, 2024. [Available here]
AI-Enabled Influence Operations: The Threat to the UK General Election, Centre for Emerging Technology and Security, Stockwell et al, 2024. [Available here]
Not even Spotify is safe from AI slop, Lopatto, 2024. [Available here]
Non-consensual Synthetic Intimate Imagery, Umbach, Henry, Beard, Berryessa, 2024. [Available here]
Deepfake Porn Is Becoming a Crisis in Schools, The Guardian, 2024. [Available here]
Alberto Brandolini, Twitter, 2014. [Available here]
Thinking Big in Data Geography: Mixed Methods and Brandolini's Law, Thatcher et al, 2018.
The Spread of True and False News Online, MIT Media Lab, 2018. [Available here]
The Polarization Loop: How Emotions Drive Propagation of Disinformation in Online Media, MDPI, 2024. [Available here]
The Spread of True and False News Online, Vosoughi, Roy, Aral, Science, 2018. [Available here]
People Are Poorly Equipped to Detect AI-Powered Voice Clones, Nightingale, Cooper, Farid, 2025. [Available here]
Regulation (EU) 2024/1689 of the European Parliament and of the Council (AI Act), European Union, 2024. [Available here]
Defending Democracy from Deepfake Deception Act, State of California, 2024. [Available here]
Online Safety Act 2023, United Kingdom. [Available here]
Methods for the Administration of Generative Artificial Intelligence Services, Cyberspace Administration of China, People's Republic of China, 2023. [Available here]
Coalition for Content Provenance and Authenticity (C2PA) Specification, C2PA, 2024. [Available here]
Synthetic Media Policy: Provenance and Authentication, Tech Policy Press, 2025. [Available here]
A Review of Audio Fingerprinting, Cano and Batlle, 2005. [Available here]
Digital Fingerprinting on Multimedia, Chen, Gan, Yu, 2024. [Available here]
A Comprehensive Real-World Assessment of Audio Watermarking Algorithms: Will They Survive Neural Codecs?, Özer et al., 2025. [Available here]
Building Trust in Multimedia Authenticity Through International Standards, Buttle and Parokkil, 2025. [Available here]
Facts Not Fakes: Strengthening Information Integrity, OECD, 2024. [Available here]
Overpromising on Digital Provenance and Security, RAND Corporation, 2025. [Available here]
Pohl, R.F. (ed.) (2012) Cognitive Illusions: A Handbook on Fallacies and Biases in Thinking, Judgement and Memory. London: Psychology Press. P. 79.
Deepfake Pornography Is Spreading Among Teenagers, ABC News Australia, 2024. [Available here]