
Managing Risks of Generative AI in Academic Publishing

Summary
AI tools such as large language models (LLMs) are being increasingly integrated into scientific workflows, but the implications of this integration remain elusive.
These tools can potentially aid researchers in finding new scientific connections, summarising large data, detecting patterns, and improving writing.
However, the risks involve propagating bias in data, fabricating information, lowering reproducibility, and facilitating the production of fraudulent scientific content aimed at exploiting “productivity” incentives.
To avoid these risks, academic publishers have produced policies to guide authors, editors, and reviewers in incorporating these AI tools in their workflows, focusing on preserving research integrity.
Our analysis shows that these policies from top publishers focus on short-term effects, lack specificity and do not include details on enforcement and consequences for non-compliance.
Our key recommendations call for standardization across publishers, clear enforcement statements and constant re-evaluation of policies in parallel to progress in the AI field. Policymakers should monitor AI in Science and fund initiatives supporting scientific integrity.
The rise of AI in Academic Publishing
Academic publishing is a foundational pillar of knowledge production, shaping laws, regulations, public policy, and technological innovation. Policymakers, industry leaders, and academic institutions rely on published research to guide critical decisions. Typical academic publications include journal articles, books, reports, conference proceedings, datasets, and software, to name a few. The integrity of this research is paramount; it must be verifiable, replicable, and trustworthy. However, the rise of generative artificial Intelligence (AI) presents unprecedented challenges to academic publishing, threatening the credibility of scientific literature. This report aims to bridge the gap between AI’s transformative potential and the necessary safeguards required to maintain rigorous academic standards.
Artificial Intelligence is a broad concept that refers to a collection of technologies that simulate aspects of human cognition through advanced mathematical and computational methods. AI technologies include Large Language Models (LLMs) and Generative AI (GenAI), which are built using techniques such as Machine Learning and Neural Networks. Some AI models specialize in generating text (e.g., ChatGPT), images (e.g., Midjourney), or videos (e.g., Veo), while others assist in mathematical reasoning (e.g., Mathematica). We focus on LLMs and GenAI due to their remarkable ability to generate and classify content based on patterns learned from large-scale training data. For simplicity, we will refer to them as AI tools.
Use of AI tools is growing rapidly in scientific writing and academic publishing. As elsewhere in the economy, its potential benefits are significant, enabling overcoming human limits of knowledge acquisition, accelerating new discoveries, or making possible new approaches that can help expand human knowledge and solve more real-world problems.
For example, AI can assist researchers by connecting research problems not explored before, or indicate approaches unlikely to be successful. It can also improve text clarity, detect logical inconsistencies, potentially a boon to the many researchers for whom English is a second language. AI can summarise large, complex texts, aiding researchers to take more information into context when making decisions. Tools can also identify patterns in data or assist in brainstorming hypotheses, potentially increasing researchers' productivity.
Until now, there is no reliable way to know precisely how widespread the use of AI is in academic publishing, but scientists have begun to investigate, and two recent papers estimated that 17.5% of computer science papers looked at and 16.9% of peer review text had at least some content drafted by AI [1].
Understanding the Risks of LLMs
Like all powerful new tools, LLMs used in academic research and publishing come with risks as well as benefits. The UK Research Integrity Office, an independent advisory body, has warned that LLMs are “not intelligent” and generally do not exhibit “explicit knowledge”, and has called on researchers to exercise great caution in their use [2]. Researchers at Oxford University have warned that the use of LLMs in academic publishing pose “long-term risks to democratic societies,” which is an effect of the inability to validate truth from falsification [3].
Hallucinations: This falsification is exemplified by one of the most fundamental issues with the use of LLMs in academic publishing called “hallucinations”. LLMs can, basically, make things up, a phenomenon that has also been dubbed “careless speech”, or, to borrow the more forthright term used by Princeton professor Harry Frankfurt, “bullshit” [4]. This can include statements of fact that are in fact not so, such as scientific references that do not exist, invalid interpretations, and website links leading to invalid addresses. Another way this phenomenon could be described is as accidental misinformation. This is mainly because LLMs provide insights based on patterns and not by verifying or testing if a statement is true.
Self-reinforcing bias: Given the iterative nature of academic research, misinformation published in one study can infect future research, creating a dangerous feedback loop of AI-generated errors reinforcing themselves in the academic record. With AI models increasingly being trained on prior AI-generated outputs, the risk of self-reinforcing bias within scientific literature could grow exponentially. If left unchecked, this cycle could erode the empirical foundations of knowledge production.
LLM Bias Concerns: Several other more specific issues exist with the use of LLMs in academic writing, beginning with authorship and accountability. Whereas LLMs might be expected to be dispassionate, in fact studies have found them to display biases similar to humans, very likely reflecting such biases in the vast quantities of training data these models consume [5]. For example, when asked for career advice, many LLMs will naturally gravitate towards recommending female dominated careers to women, and male dominated careers to men [6]. LLMs also tend to mirror real-world healthcare disparities based on race and patients' background when producing recommendations [7], and many other social biases [8].
In the early period of AI use in academic research, some scientific papers which were posted on pre-print open-source archives cited an LLM such as ChatGPT-3 as a co-author [9]. The academic community quickly realized that this was an unacceptable transfer of responsibility away from human authors. Standard practice throughout academic publishing now is that human authors must take responsibility for everything in their papers, even if produced with the assistance of an LLM.
Another potential risk of LLM-use in academic publishing is homogenization. Multiple studies have found that LLMs can reduce the collective diversity of ideas [10]. In a field dedicated to expanding the boundaries of human knowledge, this is a worrying phenomenon, especially as we appear to be living in a time of diminishing returns from science, in the form of a long-term reduction in the disruptiveness or novelty of scientific papers and patents [11].
A further concern arises around the use of LLMs in peer review. This can save reviewers an enormous amount of time, but brings into play all the risks that a chatbot’s version of the truth might be faulty or misleading [12]. Just as authors are now generally required to take personal responsibility for everything that they submit, so too peer reviewers are expected to do the same. In addition to reliability, feeding non-peer reviewed texts into an LLM is a breach of confidentiality, and can result in the transmission of errors into the training material used by the LLM for future queries.
Last but not least, growing use of LLMs risks enabling and worsening fraud in academic publishing, known in the field as paper mills. The prevalence of faked papers or undeserved authorship, sold for a fee, is generally thought to account for about 2% of scientific papers [13]. However, some have estimated the problem of fake papers to be as high as 34% for neuroscience and 24% for medicine when screening a sample of 5000 papers [14].
The ability of LLMs to produce scientific papers at the click of a mouse that look plausible but that are entirely unsound hugely lowers costs for paper mill operations. Journals struggling with high submission volumes may inadvertently accept AI-generated fraudulent papers. The growing sophistication of AI-generated figures and statistical models further complicates detection efforts. If the publishing industry fails to establish firm policies, AI-enhanced fraudulent papers will infiltrate the academic ecosystem, diminishing the credibility of legitimate research.
The risks of AI in academic publishing are particularly acute given the pressure on researchers to publish frequently in high-impact journals. The "publish or perish" culture that dominates the field incentivizes rapid output, sometimes at the expense of rigorous verification. If LLMs are used uncritically in research, this can facilitate the proliferation of misleading conclusions that are cited, incorporated into meta-analyses, and eventually treated as established fact. Such distortions have the potential to misguide policymakers, investors, and the broader public, to erode public trust in academic research, and to dissolve shared understandings of truth itself.
Efforts to Address the Risks of LLMs
Fortunately, these risks have been apparent to many in the research community and various institutions and networks have responded with discussion papers, frameworks for safe use of LLMs, and in the case of academic publishers, guidelines for authors, editors and peer reviewers.
COPE, the Committee on Publication Ethics, has published various pieces of work aimed at making sure that AI does not compromise the academic publishing process, including guidance on authorship and AI, AI in decision making and AI and fake papers [15]. These guidelines have been referenced by some of the top publishers, including Wiley and MDPI, in their own AI policies for authors to follow.
WAME, the World Association of Medical Editors, issued four recommendations on the use of chatbots in production of scholarly publications in January 2023: only humans can be authors, authors should acknowledge the source of their materials, authors must take public responsibility for their work, and editors need appropriate digital tools to deal with use of chatbots. In the face of a rapid increase in use of LLMs, the organization reissued its guidance just five months later, adding a fifth recommendation that editors and reviewers should specify, to authors and each other, any use of chatbots in evaluation of the manuscript and generation of reviews and correspondence [16].
STM Association - the International Association of Scientific, Technical & Medical Publishers - issued guidelines for the use of generative AI in scholarly publications in December 2023, including specific recommendations for authors, editorial teams, reviewers, third-party service providers, and readers [17].
Along with these institutional efforts, the publishers themselves have also rapidly issued recommendations and guidance covering their journals and other publications, and this report focuses on academic publishers in much more detail. Despite these efforts by both parties to provide guidelines for authors, inconsistencies between the guidelines exist. Discrepancies between publisher guidelines leave authors unsure of the best practice for the use of LLM in the writing process of their manuscript. Moreover, inconsistencies in guidelines allow for many risks associated with using LLMs to seep into scientific literature. For these reasons, we found it imperative to review the AI guidelines and policies that publishing bodies provide to their authors. Our review highlights the inconsistencies in these policies, aiming to encourage publishers to refine and standardize their policies for the future.
Review of Top Publishers
Our research focuses on the global industry leaders in English-language academic publishing worldwide, defined as those responsible for the largest number of items published between 2012 and 2023. We counted items on OpenAlex, an open source repository for academic works widely used for scientific research in Scientometrics and Meta Science studies [18]. These included journal articles, conference proceedings, book chapters, datasets, preprints, and other works.
Our analysis of AI policies focuses on the top 12 publishing organizations, which are based in six countries (Switzerland, Germany, Britain, Australia, Netherlands and the United States), but operate world-wide. Each of these publishers houses hundreds to thousands of peer-reviewed journals in multiple subject areas. This analysis confirmed that the academic publishing sector is highly concentrated. Out of 9,384 publishers identified, Elsevier was responsible for 16.5 million publications, or 18% of the total published; the top four publishers were responsible for more than half of all publications, and the top 12 for just over two-thirds.

Table 1. List of top 12 publishers and corresponding number of publications between 2012 and 2023.
After identifying these top publishers, a thorough search of their websites was conducted to identify any references to AI, including: guidelines for authors in carrying out data analysis and writing manuscripts, guidelines for peer reviewers when looking at draft papers, and guidelines for editors when reviewing submitted materials and deciding what to publish. The majority were found in “ethics” or “author information” sections of publisher websites. The full text of publisher AI policies were then copied into a separate document for automated plus manual analysis. This selection process was conducted in January of 2025.
The world’s largest academic publishers have a responsibility to lead and the scale to create a culture of high standards across their portfolio. Journal policies, where necessary, should derive from centrally defined “house” standards. If these are absent, then the result will be fragmentation and create inconsistency across different journals. This is likely to cause confusion for authors and others who manage academic publishing processes, while also contributing to a lack of accountability across the sector due to the enormous scale and diversity of academic publishing activity.
Analytical Framework for our Research
We assessed the strength of identified AI policies using a logic model [19] with five components covering both the academic publishing life cycle and aspects of particular importance for maintaining quality and reliability of academic outputs:
Inputs: the required resources to implement the policy
Activity: the process required to achieve the output
Outputs: the direct result from implementing the policy (short-term impacts)
Outcomes: what this direct result achieves (medium-term impacts)
Impact: the broader effects of the policy (long-term impacts)
After we identified the five components of each AI policy and fit them into our logic model, we further explored how these policies were enforced. The goal for this step was to gain some insight into the possible repercussions when authors did not adhere to the publisher’s guidelines.
We analysed publisher statements on use of LLMs first by using Anthropic’s Claude 3.5 Sonnet LLM, available from Oct 2024 [20]. We then manually reviewed results of this automated analysis to identify patterns of interest and to verify the model outputs. Where the model did not provide a clear or consistent classification, we made manual adjustments.
Some of the common types of publisher AI policies identified through the model are exemplified in the following Figure 1. This provides a simplified illustration of some of the most commonly identified policy components fit into the model. A more detailed policy review can be found in Appendix A.
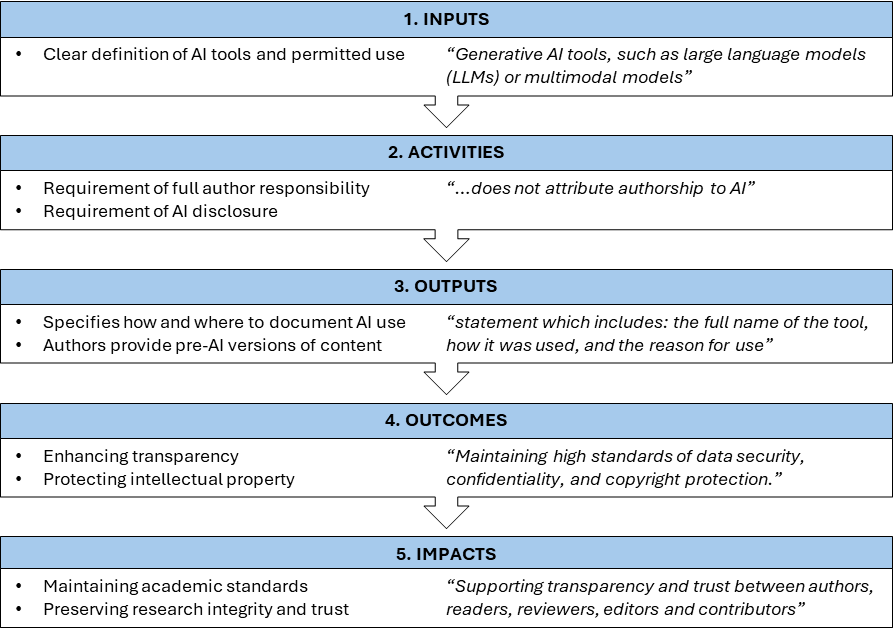
Figure 1. Illustration of the common policy components identified through our logic model with example quotes directly from the publisher’s policies.
We used a three-level scoring system for publisher AI policies:
A comprehensive score (✓) indicates that a policy explicitly and clearly states several examples from the logic model element being evaluated, such as multiple specific AI tools for inputs or detailed documentation requirements for outputs.
A basic score (⚠) is given when the policy states only a few examples from the element being evaluated or uses generic terms in the statements, for instance, mentioning AI systems without specifying types of use or providing general guidelines without implementation details.
A missing score (✗) indicates that examples from that element are not identified or mentioned in the policy, such as no discussion of long-term impacts or no specified outcome measures.
Our Findings
Our analysis shows that all top academic publishers have introduced at least some policies on AI use. The policies have some areas of strength and weakness, with varying levels of focus and comprehensiveness. We also aggregated publishers’ policy coverage and produced a total rating using: 0 indicating missing, 1 indicating basic, and 2 indicating comprehensive score. Table 2 summarises our main results:

Table 2. Policy review scoring system based on the logic model definitions. Overall rating defined as ✓:2, ⚠:1, ✗:0 where the rows sum up to 10 and columns to 24.
Strength: The Activities and the Outputs
The publishers surveyed do well in two areas based on our logic model: the Activities and the Outputs.
The main themes that publishers focused on in Activities and Outputs included:
Disclosure of the use of AI – typically they asked for this to be disclosed during the submission process or to be specified in sections such as the results or the acknowledgments sections.
Not allowing any AI to be listed as a co-author on the paper – the authors had to take full responsibility for all the work produced and submitted
Clear requirements for editors to not upload research papers into any LLM software to preserve confidentiality
Most publishers are consistent with their Activities coverage, with 10 out of 12 showing being comprehensive. These requirements typically include specific disclosure procedures, verification processes, and clear guidelines for different stakeholders. For example, MDPI requires authors to declare their use of AI “in the submission process,” while Elsevier specifies that “all work should be reviewed and edited carefully” because of AI’s ability to generate incorrect information. Further details are provided such as with Taylor & Francis, who “does not permit the use of Generative AI in the creation and manipulation of images and figures, or original research data.” These are all very clear examples of guidelines for authors to follow.
The Outputs also show high levels of consistency and comprehensive coverage across almost all the publications. Eleven out of 12 publishers provided clear requirements and only Wolters Kluwer had lacked clarity for their Outputs. The Outputs ranged from specific disclosure formats to detailed documentation requirements, such as Taylor & Francis requiring “the full name of the tool used, how it was used, and the reason for use.” Similarly, Wiley requires authors to disclose AI use “in the Methods or Acknowledgements section.” Most authors also mention AI tools not fulfilling authorship requirements, such as SAGE stating that “AI bots such as ChatGPT should not be listed as an author”. Through describing these qualitative indicators to detect AI use and misuse, SAGE further detailed the consequences of not following the policies by describing investigations into possible “inappropriate or undisclosed use of Generative AI” with possible manuscript rejection, being one of the few publishers to explicitly mention consequences.
The overall clarity between most of the publishers of explaining Activities and Outputs indicates an understanding of immediate procedural needs and the scope of AI applications. Many publishers also refer to the Committee on Publication Ethics (COPE) statement on Authorship and AI tools [21].
Mixed: The Inputs
Publishers show mixed coverage when it comes to the inputs. Seven out of 12 publishers provide comprehensive definitions of AI tools and resources. For example, Taylor & Francis clearly specifies “Generative AI tools, such as large language models (LLMs) or multimodal models,” which provides a clear definition of the type of AI they are referring to in their policy. The policy provided by Elsevier is similarly specific by mentioning that their “policy only refers to the writing process, and not to the use of AI tools to analyze and draw insights from data as part of the research process,” which clearly specifies the type of AI their policy is referring to. On the other hand, IEEE only specifies “content generated by artificial intelligence” without further indication on whether they include LLMs in their policy, though they later mention generated “text” which would imply the use of an LLM or other forms of generative AI. The lack of clarity within this AI definition is evident. If authors do not have a clear definition of which AI tools are covered by these policies, then there are more risks for misinterpretations of the policies provided by these publishers.
Weakness: The Medium-term Outcomes and Long-term Impacts
The weakest coverage was found with the final two logic model areas including the Outcomes and the Impacts. Only five publishers demonstrate a comprehensive coverage of Outcomes, while four show only basic coverage, and the remaining three show no information on Outcomes at all. Elsevier is specific in their Outcome measures stating that declaring AI use “supports transparency and trust between authors.” Springer Nature is also specific in their policy explaining that by explaining the use of AI, it “ensures confidence and trust in [their] products and tools.” We found that publishers with strong Outcome measures typically focused on these specific areas:
The importance of integrity and quality assurance
Transparency within the scientific community and maintaining trust
Confidentiality and data security
Protection from plagiarism and copyright issues
Other publishers were not this specific and did not provide metrics or measurement frameworks. SAGE, for instance, only references “ethical use of such technology,” MDPI only mentions liability to “breach publication ethics,” and Wiley only mentions the need for “full transparency.” These very basic Outcome measures hint at the overall importance of these policies, but the pattern suggests a significant gap in how publishers plan to enforce their policies and measure their effectiveness. This limitation makes it difficult to assess how these policies will achieve their intended outcome goals.
Finally, the most significant gap in current AI policies related to the Impacts, which described the long-term, broader societal impacts. Only three publishers, NIH, Springer Nature, and Taylor & Francis demonstrated comprehensive consideration of the wider implications of these policies. Springer Nature, for example, described the goals of their AI policy to be “to ensure their quality, reliability and trustworthiness to prevent negative real world impact on people or the environment.” Taylor & Francis similarly described broader impacts with “enhancing idea generation and exploration, supporting authors to express content in a non-native language, and accelerating the research and dissemination process.” The main Impact themes identified by these three publishers include:
Preserving research integrity
Maintaining the rigorous standards of academia
Improving the accessibility of research
Advancing scientific communication
Improving the dissemination of knowledge
The remaining publishers were not so clear with their Impact measures, with two publishers showing some basic mention of overall Impacts such as University of Oxford who only described “publishing values” which included “quality, integrity, and trust,” giving no further specifications. The remaining seven publishers showed fewer considerations with policies that focus mostly on immediate compliance rather than broader implications for academic publishing. Even among publishers with otherwise comprehensive policies, the approach to long-term Impacts remains limited.
Publisher League Table
Our analysis not only points to strengths and weaknesses across the sector, but also reveals a clear gradient in how well individual publishers are responding to the challenge of AI. We classify the world’s top 12 publishers into the following groups:
Comprehensive Coverage
Publishers whose Overall Rating falls in the top quarter, that is, a value higher than 7.5. Five publishers (NIH, Springer Nature, Elsevier, Taylor & Francis and University of Oxford) demonstrate strong coverage across most elements. These policies typically feature:
Clear definitions of AI and instructions for authors
Clear methods for implementation
Mention of enforcement procedures
Consideration of broader implications
Mixed Coverage
Publishers whose Overall Rating falls in the medium-high quarter, a value between 5 and 7.5. Five publishers (Wiley, SAGE, MDPI, University of Cambridge, and IEEE) show strong immediate requirements but weaker long-term considerations. These policies typically provide:
Mostly clear guidelines for authors
Specific requirements for disclosure
Limited medium-term Outcome measures
No consideration for broader implications
Basic Coverage
Publishers whose Overall Rating falls below the medium quarter, a value lower or equal to 5. Two publishers (Wolters Kluwer and De Gruyter) focus primarily on immediate requirements or lack specificity in their policies. These policies typically offer:
Basic AI use guidelines
Simple documentation requirements, sometimes unclear or unspecified
Minimal or no outcome measures
No long-term impact consideration
A Stronger Framework for AI in Academic Publishing
Our analysis on the top publishers uncovered some important gaps in the current AI policies including the lack of clarity for authors as well as the lack of consistency between the groups. It is important to note that each of these top publishers oversees hundreds to thousands of individual journals. These journals themselves may have additional AI specifications for their authors, but our analysis specifically focuses on exploring the publishing groups because we believe in the importance for AI risks to be managed uniformly across varying scientific fields and academic works. Nevertheless, we acknowledge that some sub-publishers, such as in the Nature group, may have more detailed policies, and we appreciate their efforts to expand the general publisher-provided policies. However, publishers as the overhead bodies, have the responsibility to provide effective policies and not delegate it to individual journals. The goal should be the same: to reduce as much as possible accidental or deliberate inaccuracies and falsehood in published scientific works.
The variation in policy comprehensiveness has significant implications for academic publishing preparedness as the use of LLMs grows. Publishers with more comprehensive policies provide clearer guidance for authors, editors, and reviewers, potentially leading to more consistent and responsible AI use in academic publishing. Our research shows that even the world’s top 12 publishers lack policy consistency. However, smaller publishing bodies are likely to be similar, or worse. Despite smaller publishing bodies yielding less publications, they still correspond to a third of the total publications when combined together, with millions of publications per year. Even higher unpreparedness risks might be lurking behind smaller, under-the-radar publishers.
Our Recommendations
Theme 1: Standardization
A need for greater standardization across publishers is evident from our review. We found significant consistency in Activities and Outputs because most publishers provided clear steps for authors to follow. However, there is still room for further refinement.
Publishers varied in their guidelines on disclosure of AI use. Some instruct authors to include in the methods sections, in acknowledgements, or to disclose during the submission process. Guidelines on how to disclose AI use should be standardized as it is for acknowledgements and data statements in articles, increasing transparency and facilitating finding the information.
Proper definitions of AI within policies are needed for all the publishers. As evident from our review, some provided excellent definitions, specifying the policy relating to LLM use in the writing process. Others only mentioned AI as a generic term without further explanation of the type of AI the policy covers. Without clear definitions, authors will find it hard to understand whether these policies refer to their work; therefore, aligning these policy definitions between publishers is important. Furthermore, clarity is needed on the proper use of LLM, separate from other uses of AI. LLM is commonly used for text generation but some policies, such as ones provided by Wiley and SAGE, specifically noted that help with grammar and basic editing are not covered by the AI policies and do not need to be disclosed. It is up to the author to decide whether help with their editing is minor enough not to warrant disclosure, but where we draw the line between small grammar fixes and full-paragraph rewrites by AI is unclear. Publishers should realise these risks and address them with more clarity in their policies so that authors and editors know exactly what should and should not be disclosed.
In addition, publishers need to improve the accessibility and intelligibility of AI policies. Despite some publishers showing relatively good coverage of the policy requirements, this does not translate to ease of compliance for authors. Our manual review and verification process revealed real difficulties with finding some of these policies. Many were buried behind multiple web pages and/or stored as separate PDF documents. Even if the policy exists, if it is not easy to find, it will be difficult to follow. This is exemplified by the seemingly comprehensive NIH AI policies. NIH stands out as one of the only organizations apart from Taylor & Francis with comprehensive coverage (✓) across all five of our logic model elements (see Table 2). This likely reflects its role as a public institution with broader responsibilities to the research ecosystem such as being a major funding institution. However, an author would still need to review several individual documents to fully understand all AI-related policies instead of consulting a single point of information. It would be entirely up to the author to filter through the plethora of documents and seek out information on their own, which is unlikely. A much more realistic approach would be to have the policies included as one webpage, as is done by SAGE and Taylor & Francis, and to include this webpage in the ‘author information’ section of the publisher websites.
Theme 2: The Need for Enforcement
To ensure key outcomes, such as research integrity, almost all publishers need a clearer focus on enforcement.
Frameworks and procedures for AI detection should be considered, for example AI-detection tools such as AIRA and Paperpal Preflight [22]. However, publishers should proceed with caution because AI detection has varying degrees of success and is quickly outdated as LLMs gain new capabilities. Techniques which are currently promising look for “tortured phrases,” which describe unconventional phrases or jargon language found in place of established terms [23]. Requirements should deal with falsified images as well as text [24]. Elsevier current policy states that, for publication of images, authors may be asked to provide pre-AI adjusted versions. Verification of authenticity by providing original versions of works is an excellent way to ensure authors are transparent.
Random sampling of published work for further review should become more widespread. Random sampling would be particularly useful because LLMs have great potential to facilitate fraud. Its wider use could serve to lower the risk of falsified papers slipping into the scientific literature.
The sector needs to develop clearer success metrics. Current AI policies are characterised by recommendations and reliance on self-reporting, but very little indication of how success in avoiding harm is to be measured and whether, in fact, it is being achieved. Examples of metrics include providing statistics on papers rejected because of abuse of AI tools and the success rate of screened manuscripts.
Theme 3: Staying Up to Date
AI is developing so rapidly that, while clearer norms over its use in scientific publishing are needed immediately, so too are mechanisms that will enable practices “to grow with the technology as LLM research finds remedies and develops complementary tools” [1].
Publishers should be vigilant to the impacts of LLMs on the research ecosystem and society, and ensure that these considerations are fed back into specific rules and guidelines on AI. Improvements in accessibility and intelligibility will facilitate this process.
Researchers and scientists should be made aware of the increasing trend of LLMs use in publishing. Encouraging researchers to scrutinise research findings and learn methods of detecting possible AI-generated publications is essential to maintaining the research community's trust and accountability. Publishers should consider having a system to easily flag potential AI-generated papers so researchers or the interested public who find questionable publications can have them scrutinised.
Publishers, along with editors and researchers, should set up forums or commissions to frequently evaluate the effectiveness of AI policies and adjust them as needed. Collective policy designs will ensure that all interests are represented in the policies. The resulting policies can then be adapted by publishers, reducing duplicated efforts, facilitating adoption and updates.
Theme 4: Action by Policy-makers
To ensure long-lasting and systemic changes, policymakers and national research funding agencies should watch the sector closely for signs of AI risks to academic integrity not being managed properly, and become role models in good practices.
Policy-makers should monitor developments in the use of AI in academic research and academic research publishing, as well as industry and professional standards bodies plus academic publishing companies, keep under evaluation the potential need for government direction, funding or legal regulations if risks of AI use are not being adequately managed, and set overall standards. In this context the European Commission’s publication of Guidelines on the responsible use of AI in research [25] is a good first step.
Publicly-backed research funding agencies should set clear requirements on AI use in funding applications by researchers, including elements on transparency, confidentiality, falsification, fabrication and plagiarism. In this context, principles developed by the Research Funders Policy Group [26] in Britain, and subsequently funding body UK Research & Innovation [27], as well as the US National Science Foundation [28], contain points worth emulating.
To counter the risks that AI might lead to an increase in fraudulent paper mill activity, policymakers should give moral and practical support to publishing industry efforts to counter paper mills, such as UNITED2ACT [29].
Conclusion
Our review of major academic publishers reveals that many policies have significant gaps, and most lack explicit enforcement strategies. Few publishers provide concrete guidelines on how AI use should be disclosed, and even fewer outline consequences for violations. The absence of standardized AI policies creates an uneven landscape in which some disciplines may be more vulnerable to AI-generated misinformation than others. Furthermore, with the rapid development of AI models, policies that fail to anticipate new advancements risk becoming obsolete.
Our findings indicate that while academic publishers have established basic frameworks for managing AI use, their approach remains hands-off and leaves most onus and responsibilities on the researchers through self-reporting and trust-based mechanisms. This practice might prove to be insufficient in the face of more sophisticated LLMs, the ever-present risk of fraudulent behaviour, evidenced through paper mill articles and journals, and economic and professional incentives for all participants to value the volume of publications and citations over all else.
This report provides critical analysis and insight into the details and scope of the problem, setting up our capacity to address them. The findings presented here serve as both a warning and a call to action, urging publishers, policymakers, and research institutions to establish robust, enforceable frameworks for AI use in academic publishing. By exposing inconsistencies in AI policy enforcement, highlighting vulnerabilities in the peer review process, and proposing clear strategies for maintaining research integrity, we intend to contribute to the development of a more transparent, accountable, and resilient academic publishing system.
The challenges are indeed significant. Like the Red Queen in Lewis Carroll’s “Through the Looking Glass”, by running as fast as it can, the sector only stays in the same place. To be assured of making real progress it needs to run twice as fast. Strong networks and dialogue between publishers, and between publishers and standards bodies like COPE are essential to reducing inconsistencies and enabling the sector to keep up with the ever-changing risk profile of AI in academic publishing.
Ultimately, though, our perspective on AI and science is an optimistic one. Firstly, because most of the issues associated with the use of LLMs, such as errors, plagiarism, fabrication, or discrimination, are known. Many promising initiatives address these challenges and existing frameworks for risk assessment [30] and proportionate regulation can be adapted while new ones are developed for uncharted AI territory. And secondly, because - with appropriate limitations and safeguards - the evidence is already clear that AI can significantly advance humanity’s scientific enterprise.
References
Binz, M. et al. How should the advancement of large language models affect the practice of science? Proc. Natl. Acad. Sci. U. S. A. 122, e2401227121 (2025).
AI in research - UK Research Integrity Office. https://ukrio.org/ukrio-resources/ai-in-research/.
Large Language Models pose a risk to society and need tighter regulation, say Oxford researchers | University of Oxford. https://www.ox.ac.uk/news/2024-08-07-large-language-models-pose-risk-society-and-need-tighter-regulation-say-oxford (2024).
Hicks, M. T., Humphries, J. & Slater, J. ChatGPT is bullshit. Ethics Inf. Technol. 26, 38 (2024).
Acerbi, A. & Stubbersfield, J. M. Large language models show human-like content biases in transmission chain experiments. Proc. Natl. Acad. Sci. 120, e2313790120 (2023).
Kotek, H., Dockum, R. & Sun, D. Gender bias and stereotypes in Large Language Models. in Proceedings of The ACM Collective Intelligence Conference 12–24 (ACM, Delft Netherlands, 2023). doi:10.1145/3582269.3615599.
Yang, Y., Liu, X., Jin, Q., Huang, F. & Lu, Z. Unmasking and quantifying racial bias of large language models in medical report generation. Commun. Med. 4, 1–6 (2024).
Liang, P. P., Wu, C., Morency, L.-P. & Salakhutdinov, R. Towards Understanding and Mitigating Social Biases in Language Models. in Proceedings of the 38th International Conference on Machine Learning 6565–6576 (PMLR, 2021).
Stokel-Walker, C. ChatGPT listed as author on research papers: many scientists disapprove. Nature 613, 620–621 (2023).
Moon, K., Green, A. & Kushlev, K. Homogenizing Effect of a Large Language Model (LLM) on Creative Diversity: An Empirical Comparison of Human and ChatGPT Writing. Preprint at https://doi.org/10.31234/osf.io/8p9wu_v2 (2025).
Park, M., Leahey, E. & Funk, R. J. Papers and patents are becoming less disruptive over time. Nature 613, 138–144 (2023).
Researchers warned against using AI to peer review academic papers. https://www.semafor.com/article/05/08/2024/researchers-warned-against-using-ai-to-peer-review-academic-papers (2024).
Parker, L., Boughton, S., Bero, L. & Byrne, J. A. Paper mill challenges: past, present, and future. J. Clin. Epidemiol. 176, 111549 (2024).
Fake scientific papers are alarmingly common. https://www.science.org/content/article/fake-scientific-papers-are-alarmingly-common.
COPE Focus on artificial intelligence. COPE: Committee on Publication Ethics https://publicationethics.org/cope-focus/cope-focus-artificial-intelligence (2024).
Zielinski, C. et al. Chatbots, generative AI, and scholarly manuscripts: WAME recommendations on chatbots and generative artificial intelligence in relation to scholarly publications. Curr. Med. Res. Opin. 40, 11–13 (2024).
Generative AI in Scholarly Communications: Ethical and Practical Guidelines for the Use of Generative AI in the Publication Process. https://stm-assoc.org/new-white-paper-launch-generative-ai-in-scholarly-communications/ (2023).
Works Citing OpenAlex. OpenAlex https://openalex.org/works-citing-openalex.
Quinn, D. & Madden, C. Frameworks for Policy Planning and Evaluation. (2021).
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. https://www.anthropic.com/news/3-5-models-and-computer-use.
Authorship and AI tools. COPE: Committee on Publication Ethics https://publicationethics.org/guidance/cope-position/authorship-and-ai-tools (2023).
Artificial intelligence: lightning talk summary. COPE: Committee on Publication Ethics https://publicationethics.org/news-opinion/artificial-intelligence-lightning-talk-summary (2024).
Cabanac, G. Decontamination of the Scientific Literature. https://ut3-toulouseinp.hal.science/hal-03835147 (2022) doi:10.48550/arXiv.2210.15912.
Jones, P. Feasibility of Technical Solutions for the Detection of Falsified Images in Research. https://s3.eu-west-2.amazonaws.com/stm.offloadmedia/wp-content/uploads/2025/02/06115634/Feasibility-of-technical-solutions-for-the-detection-of-falsified-images-in-research_final.pdf (2024).
Living Guidelines on the Responsible Use of Generative AI in Research. https://research-and-innovation.ec.europa.eu/document/2b6cf7e5-36ac-41cb-aab5-0d32050143dc_en (2024).
Funders joint statement: use of generative AI tools in funding applications and assessment. Wellcome https://wellcome.org/who-we-are/positions-and-statements/joint-statement-generative-ai (2023).
Use of generative AI in application preparation and assessment. https://www.ukri.org/news/use-of-generative-ai-in-application-preparation-and-assessment/ (2024).
Notice to research community: Use of generative artificial intelligence technology in the NSF merit review process | NSF - National Science Foundation. https://www.nsf.gov/news/notice-to-the-research-community-on-ai (2023).
United2Act. United2Act https://united2act.org/.
Kondor, D., Hafez, V., Shankar, S., Wazir, R. & Karimi, F. Complex systems perspective in assessing risks in artificial intelligence. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 382, 20240109 (2024).
Appendices in the Report PDF